[Research] 초짜 개발자의 AI 서비스 삽질기 Part 1

0. 무슨 일이 있었는가…
하하 j0ker 입니다! 왜 또 이렇게 오랜만에 글을 쓰냐구요? 마지막으로 쓴 글이 언제지… 아 8월… 하하… 살려주세요… 다음에는 좀 더 재미있는 글을 바치겠나이다…

오늘은 이전 연구글들과 달리 간단하게 개발했던 프로젝트에 대해 얘기해볼까 합니다.
지난 8월 30일, 제 31회 해킹캠프가 진행되었습니다. 저는 그보다 대략 2주 전에 갑자기 운영진으로부터 연락을 받게됩니다…
예… 원래 발표하시려던 분이 급작스럽게 발표를 못하신다고 연락이 와서 대타를 구하게 되었던 거였죠. 저는 원래 이틀날에 가서 멘티 발표하는 거 듣고 저녁에 운영진분들이랑 술이나 먹어야겠다 싶었는데… 발표를 하게되었습니다 ㅋㅋㅋ 그래서 발표 준비를 좀 하고 일주일 정도 시간 여유가 있었는데… 제가 일 벌리는데는 선수라 뭔가를 더 하고 싶었습니다.
1. 기획 시작
잠깐 근황을 얘기하자면, 최근 L0ch와 Hacky-AI라는 스타트업을 창업해서 보안 솔루션을 개발하고 있습니다.(관심있으시면 저희 홈페이지를 방문해주세요!) 스타트업을 하면서 가장 중요하다고 생각하는 것은 고객의 문제를 파악하고 해결법을 제시하는 것이라고 생각합니다. 그 이외에도 신경 쓸 것이 많지만… 아무튼 그래서 “발표를 듣는 사람들에게 필요한 것을 간단하게 만들어볼까?”라는 생각을 하게 되었습니다.
솔루션을 만들고 있기도 해서 AI 서비스들를 활용한 개발에 관심을 많이 가지게 되었는데요. 이 때 최대한 지키고자 했던 것들은 다음과 같습니다.
- 내가 코드를 짜지 말고 AI 서비스들이 다 작성하게 하자.
- 일주일밖에 없으니 돌아가게만 만들자.
- 사람들이 필요한 서비스를 만들자.
해킹캠프는 1일차 저녁에 CTF를 진행하는데요, 그래서 제가 가정한 것은 해킹캠프에 참여하시는 분들은 대부분 이제 막 해킹을 시작한 분들일 것이기 때문에 리버싱에는 아직 많이 익숙하지 않으실 것이다! 그러면 리버싱 보조 도구를 개발하면 좋지 않을까? 였습니다. 이정도면 그래도 혼자 3일 정도 투자하면 개발할 수 있지 않을까 싶었죠.(하지만 이것은 오만이었습니다) 좀 더 구체적으로 변수와 함수 이름을 LLM을 활용해 읽기 쉬운 이름으로 바꿔주고 함수 내용을 LLM으로 분석해 주석으로 추가하는 것까지 만들면 되겠다 싶었습니다.(IDA를 안 킨지 1년이 넘어가니 이미 오픈소스로 있는 걸 만들면서 알았습니다 하하… 뭐 그래도 제가 서비스를 만들어보는게 취지니까요)
간단하게 서비스 흐름도를 만들어보면 다음과 같습니다.
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ IDA Pro │◄──────────────►│ FastAPI │◄──────────────►│ Ollama │
│ 플러그인 │ │ 서버 │ │ LLM 서버 │
│ (Python) │ │ (Python) │ │ │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Supabase │ │ Langfuse │
│ 데이터베이스 │ │ 모니터링 │
└─────────────────┘ └─────────────────┘
2. Ollama 서버
먼저 왜 상용 서비스를 쓰지 않냐?는 질문이 드실듯 합니다. Gemini, ChatGPT 등 좋은 모델들이 얼마나 많은데 말이죠. 일단 개인적인 생각은 “이 서비스에는 작은 오픈소스 모델로도 충분하다” 였습니다. 창업 전 회사에서도 오픈소스 모델을 활용해 프로젝트를 진행했었고, 현재 연구를 진행하면서도 온프레미스 환경 구축을 위해 여러 오픈소스 모델들을 테스트해왔습니다. 아쉽게도 성능의 제한으로 큰 모델을 테스트하지 못하고 있지만요 ㅠㅠ
현재 제가 집에서 LLM 추론을 위해 사용하고 있는 기기는 맥미니 입니다. M4 Pro 칩을 탑재하고 있고, 램은 64기가 입니다. 여기에 Ollama 서버를 올리고 모델을 서빙했습니다. Ollama 홈페이지를 가보시면 램 64기가 내에서 활용할 수 있는 모델들이 많습니다.
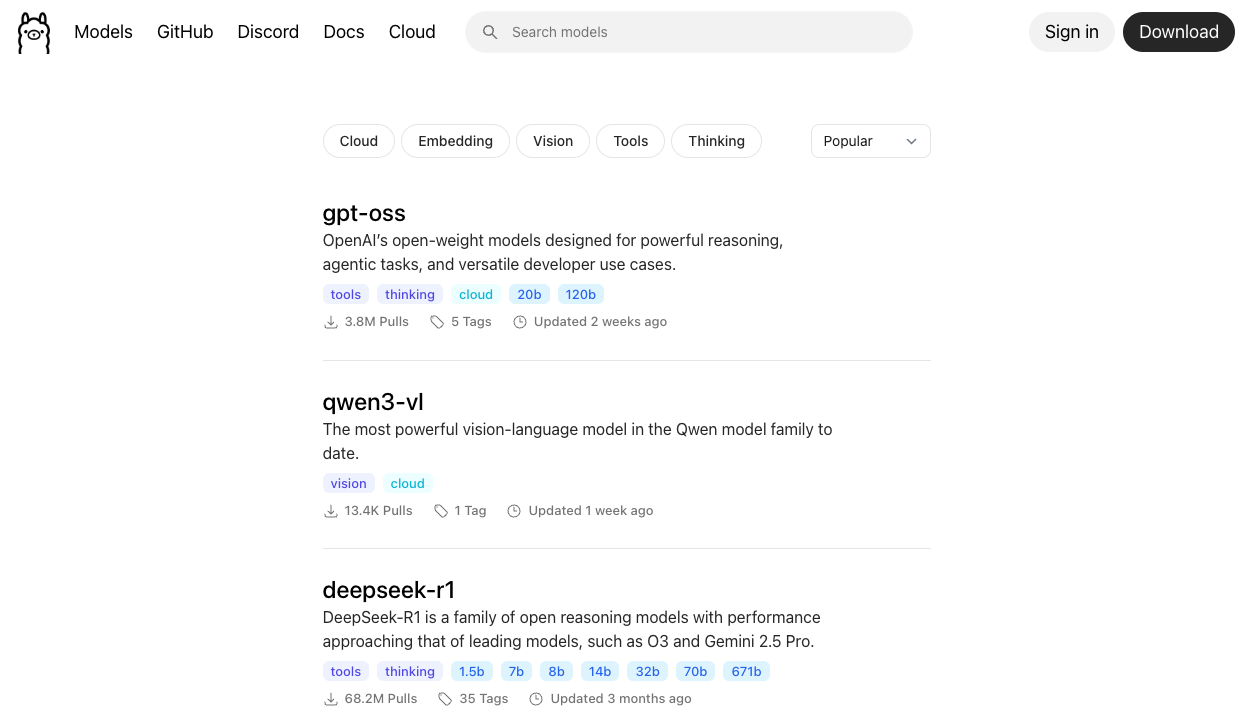
최근에 가장 인기 있는 gpt-oss, deepseek 등 모델 중에서 저는 32B 정도 크기의 모델들 중 q8로 양자화된 모델들을 좋아하는 편입니다. 간단한 이유를 들어보자면:
- 70B q4 모델들(다운받으면 약 40G 정도)을 램 64기가에서 돌릴 수는 있지만, 이 당시 70B 모델들은 나온지 조금 시간이 지난 모델들이었습니다. 또한 긴 함수들을 처리하기 위해서는 컨텍스트 윈도우를 위한 공간도 남겨둬야한다 생각해서 좀 더 작은 모델을 쓰면 좋겠다는 생각을 했습니다.
- 8월 중순쯤에 나온 핫한 모델들이 작은 모델들이 있었고 성능이 좋았습니다. gpt-oss의 경우 20B MoE 모델이 있었고, qwen3에는 32B과 30B MoE 모델이 있었죠. 이 모델들 경우, 체감상 최신 ChatGPT 4o 정도 혹은 그보다 살짝 더 높은 성능을 내는 듯 했습니다.
- 이 외에도 좀 더 작은 모델인 phi4 14B, gemma 27B 등을 제가 미리 세팅해둔 몇 개의 프롬프트를 테스트하면서 성능을 확인해봤습니다.
여러 테스트를 거친 결과 “qwen3:30b-a3b-instruct-2507-q8_0” 모델을 사용하기로 했습니다.
당연한거지만 MoE 모델이 일반 모델보다 추론속도가 훨씬 빠릅니다. Qwen3 32B q8 모델의 경우, 7 tps 정도의 속도가 나왔고 Qwen 30B MoE 모델의 경우 높으면 45 tps까지 속도가 나옵니다. 소규모 서비스에서 이정도면 충분하다고 생각했습니다.
total duration: 54.782917709s load duration: 83.491792ms prompt eval count: 2649 token(s) prompt eval duration: 4.376536583s prompt eval rate: 605.27 tokens/s eval count: 2293 token(s) eval duration: 49.986260996s eval rate: 45.87 tokens/sReasoning 모델인 qwen3:30b-a3b-thinking-2507을 사용하지 않은 이유는 프롬프트 테스트 과정에서 Reasoning이 끝나지 않은 버그가 지속적으로 나타났기 때문입니다. 당시 모델이 공개된 지 얼마 안된 모델이라 그러려니 하고 그냥 안 썼습니다.
- 다른 Reasoning 모델을 사용하지 않은 이유는 출력이 완료될 때까지 시간이 더 걸린다는 것이 문제였습니다. instruct 모델을 사용하면 어지간한 출력까지는 2분 안에 나올 수 있지만 reasoning을 하는 순간 1~2분이 추가적으로 들어가게 됩니다. 그리고 reasoning을 사용하지 않아도 성능이 충분하기도 했고요.
- 이보다 더 작은 모델을 사용하기에는 추가적인 작업이 필요했습니다. 즉, 한번에 분석하는 성능이 떨어졌습니다. phi4 14B 모델의 경우, 성능은 충분했지만 fp16 모델을 써야 성능이 쓸만한 수준으로 나왔는데, reasoning 시간이 너무 길어 실사용에는 무리가 있었습니다. 이 외 Qwen3 14B, 8B, Gemma 27B, Deepseek 14B 등을 제대로 활용하기 위해서는 프롬프트 공수가 더 필요하다고 판단했습니다.
- 이 여러가지 고려사항 중에 속도, 성능, 메모리 등을 고려했을 때 “qwen3:30b-a3b-instruct-2507-q8_0” 모델을 사용하는 것이 제일 적합하다고 판단했습니다.
모델을 정했으니 간단하게 환경변수 세팅하고 ollama serve 명령어를 통해 서버를 실행만하면 준비 끝!입니다.
2. Langfuse로 프롬프트 로깅
이것도 역시 “LangSmith 쓰면 되는거 아냐?”라는 생각이 드실겁니다. 저도 그렇게 생각합니다만… 역시 솔루션 개발 과정에서 온프레미스를 고려할 때 테스트를 해봤기 때문에 이참에 Langfuse를 써보자고 생각했습니다.
Langfuse를 서버에 설치하는 것은 어렵지 않습니다. 래포에서 받아 바로 도커로 올리면 됩니다. 그런 다음, langchain에 langfuse의 callbackhandler를 등록해주면 아래와 같이 요청들의 로깅이 시작됩니다.
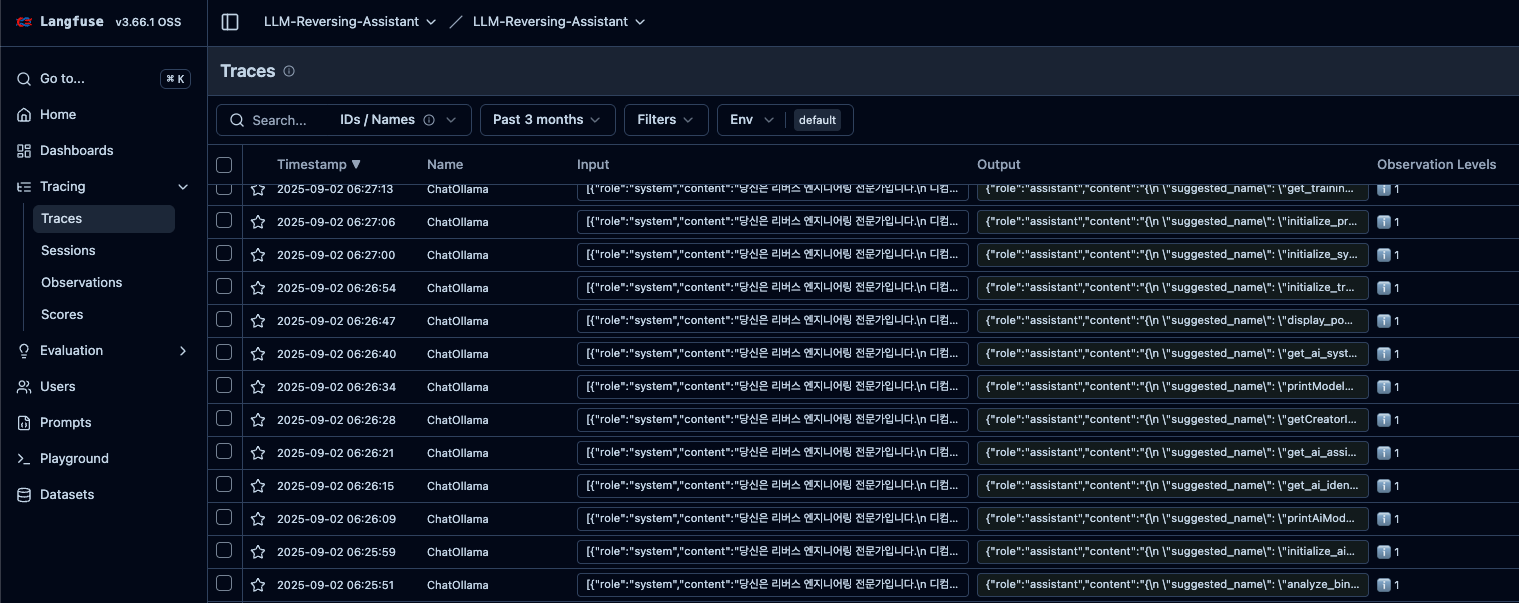
로깅을 하면 요청에 대한 응답이 제대로 전송이 되었는지, 응답의 퀄리티를 확인할 수 있습니다. 이 내용을 바탕으로 프롬프트나 실행 체인을 발전시킬 수 있겠죠.
그리고! 공격이 들어오는 것도 확인할 수 있습니다 ㅋㅋ


위와 같이 프롬프트 인젝션 공격이 날라오는 것도 확인할 수 있었습니다. 새벽까지 열심히 하셨는데… 아쉽게도 원하시는 정보는 가져가지 못하신 것 같습니다.
3. Lovable + Supabase
원래 저희 홈페이지는 Base44로 개발했었습니다. 네, 몇 달 전에 $80M에 Wix에 인수된 그 서비스입니다. 저도 이 기사를 보고 써봤는데요, 간단한 랜딩페이지를 개발하는 것까지는 괜찮았는데, 로그인 기능 이후로 문제가 많았습니다. 특히 데이터베이스를 활용하는 기능을 개발할 때는 정말 최악이었습니다.
그래서 당시 뭘 쓸까 찾아보던 중 “Lovable이라는 서비스가 요즘 핫하다더라”는 얘기를 듣고 일단 써봤습니다. 이전에 개발했던 웹페이지를 똑같이 먼저 배껴온 뒤 로그인부터 개발하기 시작했습니다. 먼저 사용자 정보를 저장하기 위해서 Supabase를 연결시켰습니다.
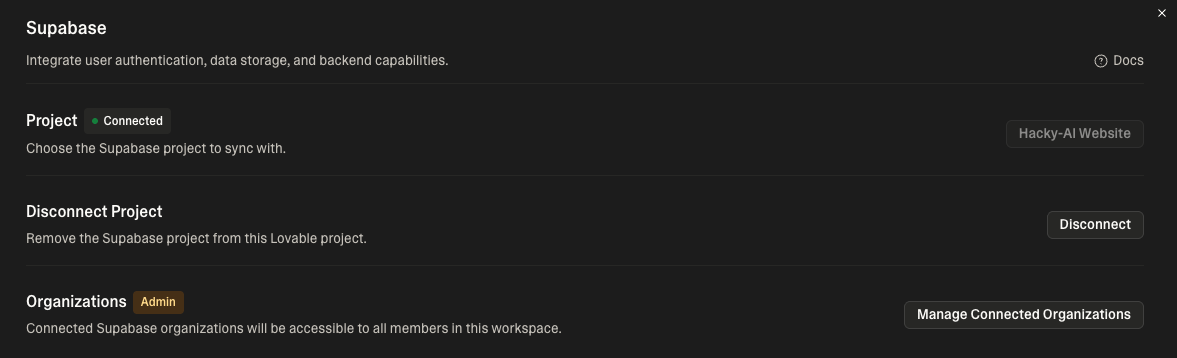
Base44와 달리 Supabase랑 바로 연동도 되고, 디비 관리하기도 편하고 여러모로 장점이 있는 것 같습니다. 물론 대규모 고객을 감당하기에는 힘들긴하겠지만요(제 지갑이) 이렇게 연동을 하고 로그인 버튼을 만들면…
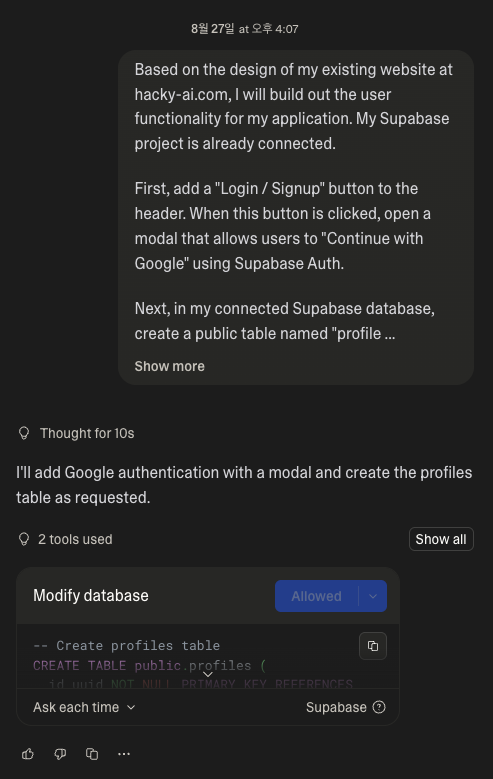
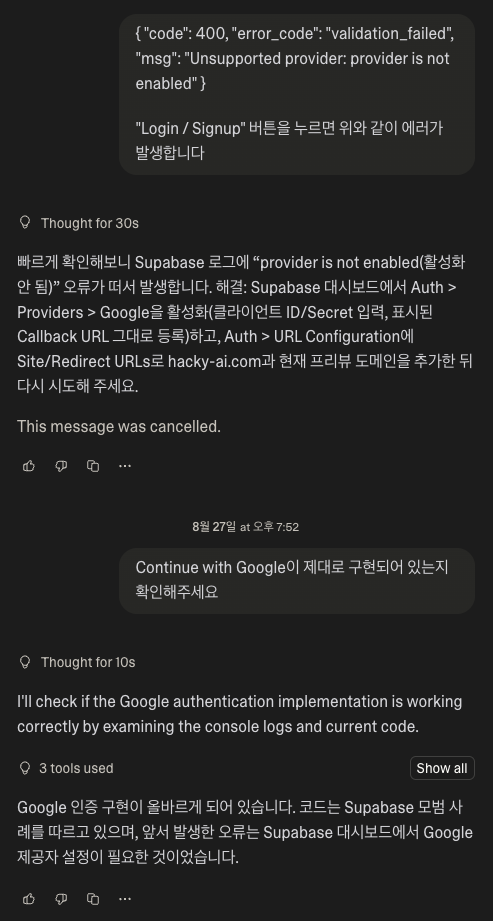
네… 뭐 쉽진 않지만 몇 번의 트라이만에 성공하긴했습니다. 로그인한 뒤에는 대시보드가 있어야겠죠? 프롬프트를 잘 작성해서 만들어줍니다.
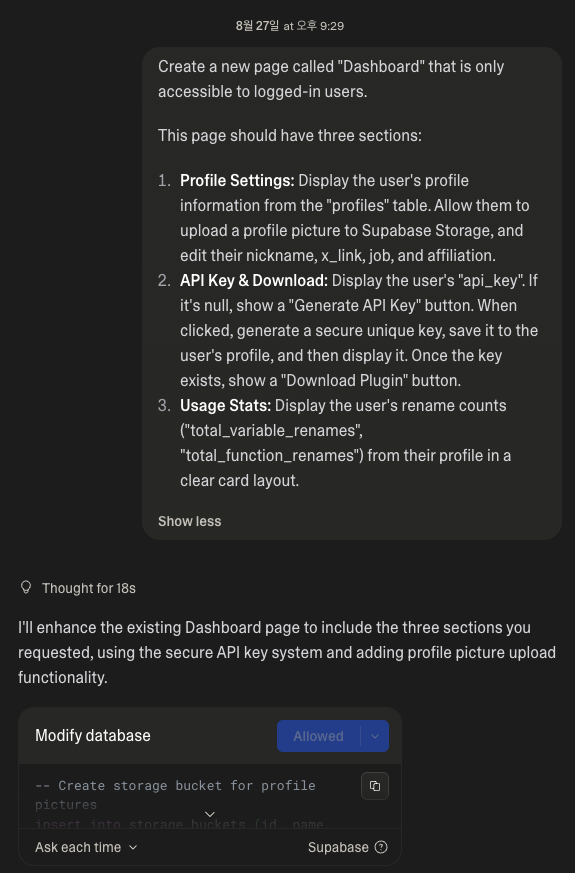
당연히 위 프롬프트 한번으로 깔끔하게 개발되지는 않습니다. 만약 한번에 됐다면 바로 Lovable 주식을 구하러 다녔을 겁니다.
아무튼 여전히 문제는 많았습니다. API 키를 랜덤하게는 잘 생성하지만 Supabase에 저장할 때 API 키 일부를 마스킹(*) 처리한 상태로 그대로 저장한다던가, 임의로 버튼을 없앤다던가 등등 자잘하게 신경써야할 것들이 좀 있었죠. 그래서 구현할 기능들의 범위를 좀 더 줄이기로 했습니다. 원래는 주간 사용량 Top 5 이런 재미요소도 넣으려고 했는데… 생각보다 프롬프팅을 많이 해야해서 일단은 넘어가기로 했습니다.
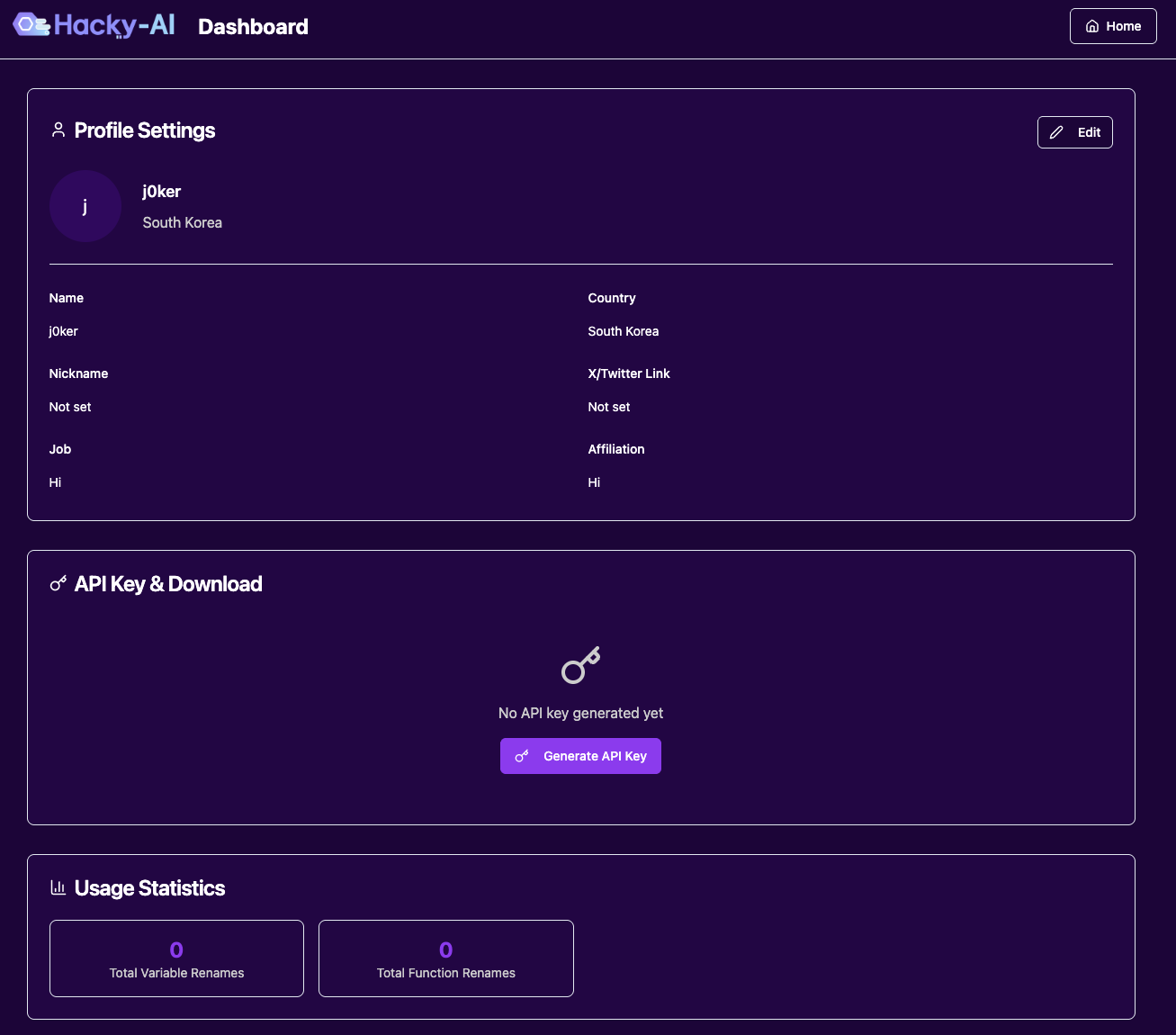
그래도 4시간 정도 삽질한 끝에 필요한 최소한의 기능들을 모두 구현할 수 있었습니다. 제 미천한 웹 개발 실력으로 직접 개발했다면 1주일은 걸렸을텐데 확실히 요즘 AI 서비스들을 사용하는게 훨씬 이득인거 같네요.
오늘은 간단하게 이정도로 마무리하겠습니다. 다음에는 나머지 개발기와 발표 현장에서는 또 어떤 일이 있었는지 다뤄보겠습니다. 그럼… 그 때까지 잘 살아있도록 빌어주세요… 바이!

본 글은 CC BY-SA 4.0 라이선스로 배포됩니다. 공유 또는 변경 시 반드시 출처를 남겨주시기 바랍니다.