[Research] LLVM based VMProtect Devirtualization: Part 1 (KR)
Introduction

안녕하세요. 오늘도 어디서인가 돌아온 banda입니다.
코드 난독화를 수행하는 대표적인 프로그램 중에 VMProtect, Themida가 있는데요. 이 중 VMProtect는 특히 가상머신(VM) 기반의 가상화, 난독화를 수행하는 프로그램으로 알려져 있습니다. VMProtect는 non-standard 가상 아키텍처를 통해 원본 코드를 독자적인 바이트코드로 변환하면서 정적 분석, 동적 분석을 매우 어렵게 만듭니다. (혹시 이전에 작성된 난독화 연구글이 궁금하다면 (👉여기로 ㅎㅎ))
그간 VMProtect 난독화 해제를 시도하려는 논문과 연구가 꾸준히 제공되어 왔는데, 오늘 필자는 이와 같은 연구 중 특히 LLVM을 활용한 난독화 해제 방법론을 중심으로 살펴보고, 난독화 해제가 어느 실현 가능할지 살펴보려고 합니다. (다만 이번 글에서는 VMP 보호 옵션 중 가상화 옵션에 대해서만 집중적으로 다룹니다.)
VMProtect
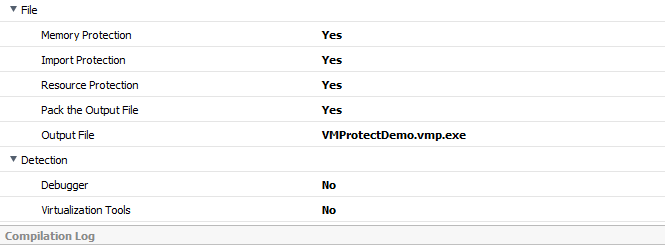
VMProtect는 Anti-Reversing 기법을 적용해 소프트웨어를 보호하는 프로그램입니다. 공식 문서에 따르면 애플리케이션 코드 보호와 크랙 방지를 위해 사용되며, 자체 스크립트 언어와 내장 디스어셈블러를 제공해 보호할 코드 영역과 빌드 동작을 세밀하게 제어할 수 있고, 주로 Windows 기반 네이티브 애플리케이션(C/C++, Delphi, Visual Basic)을 대상으로 바이너리 난독화를 수행합니다.
VMProtect 3.9.6 기준으로 난독화 옵션은 ①Memory Protection, ②Import Protection, ③Resource Protection, ④Pack the Output File, ⑤Debugger Detection, ⑥Virtualization Tools Dectection, ⑦Virtualization이 존재합니다.
이 중에서도 Virtualization(가상화)은 강력한 보호 기법으로, 원래의 x86/x64 코드를 VMProtect가 정의한 커스텀 바이트코드로 변환한 뒤, 실행 시 내장된 가상머신이 이를 해석해 동작하는 방식입니다. 또한 하나의 바이너리 안에서도 여러 종류의 VM이 혼합될 수 있으며, 엔트리포인트를 포함해 다양한 위치를 선택적으로 가상화할 수 있습니다.
VMProtect with LLVM
LLVM을 활용한 VMProtect 분석은 그동안 VM의 내부 구조를 이해하려는 정적 리프팅(Static Lifting)과, 내부 구조 대신 동작 결과에 집중하는 동적 트레이싱(Dynamic Tracing) 두 가지 케이스로 연구가 진행된 바 있습니다.
- 정적 리프팅 (Static Lifting)
첫 번째 접근법에서는 VM 내부를 White-Box로 간주해 정적 리프팅하는 방식을 사용하고 있습니다. 이 접근법을 확인해보면 VmHandler(VMProtect에서 VM을 구성하는 각 가상 명령어 핸들러)를 일일이 리버싱하여 그 동작을 분석하고, 이를 C++를 통해 Helper Function로 재구현합니다. 이후 보호된 코드의 VM 바이트코드를 이 Helper Function 호출의 연속으로 번역해 전체 프로그램을 LLVM-IR로 변환하는 방식을 사용하고 있습니다. 다만 위 접근법을 사용하기 위해 VM 아키텍처에 대한 깊은 이해가 필요합니다. (reference)
- 동적 트레이싱 (Dynamic Tracing)
두 번째 접근법은 동적 트레이싱을 통해 VM을 실행시켜 입력과 출력 사이의 관계만 추적해 함수 난독화를 해제하는 Black-Box 방식을 사용하고 있습니다. 특정 입력을 주고 프로그램을 실행해 실행된 모든 명령어를 ‘trace’로 기록하고, 이 흔적을 심볼릭 실행으로 재구성해 입출력 관계식을 도출합니다. (reference)
LLVM IR과 SSA (Single Static Assignment)
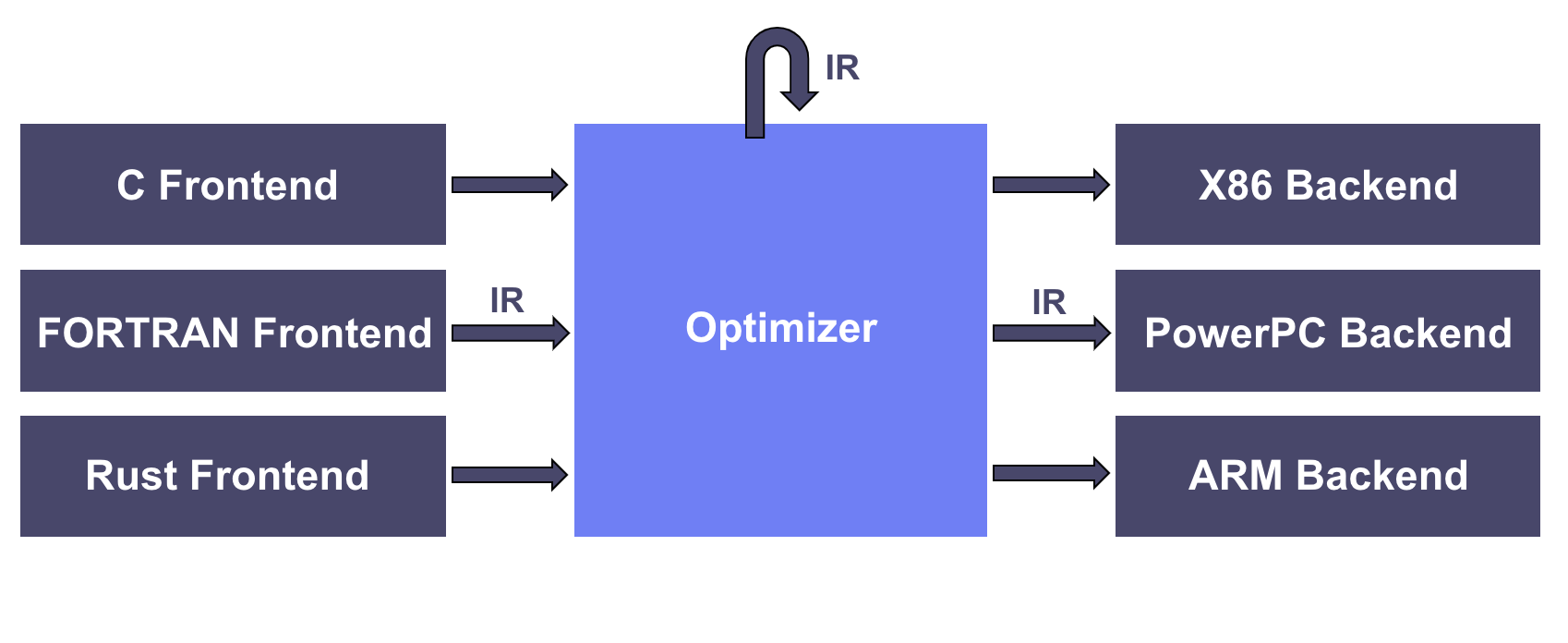
LLVM IR은 SSA(Static Single Assignment) 형식을 기반으로 하는 중간 표현(Intermediate Representation, IR)을 사용합니다. SSA(Static Single Assignment)란, 변수가 한 번만 할당된다는 원칙을 따르며, 새로운 값이 계산될 때마다 새로운 가상 레지스터(SSA 변수)가 생성되는 원리를 가지고 있습니다. 아래 어셈블리 코드와 LLVM IR 코드를 비교해봅시다.
add rax, rcx
sub rdx, rbx
sub rax, rdx%rax2 = add i64 %rax, %rcx
%rdx2 = sub i64 %rdx, %rbx
%rax3 = sub i64 %rax2, %rdx2LLVM IR 코드에서는 %rax1, %rax2처럼 변수 이름이 계속 바뀌는 것을 확인할 수 있는데요. 이유는 한 번 정의된 SSA 변수가 다시 덮어쓰지 않는다는 원칙 때문이겠죠?! 따라서 데이터 흐름과 연산 결과를 명확히 추적할 수 있다는 장점을 가지고 있습니다.
이런 SSA 형식의 LLVM-IR이 왜 VMProtect 가상화 해제에 중요할까요?
VMProtect의 가상화 핸들러는 수천 개, 그 이상의 비트 연산, 시프트, 산술 연산을 뒤섞어 노이즈를 만들며, 원래 연산을 감추기 위해 MBA(Mixed Boolen-Arithmetic)과 같은 복잡한 수식을 생성합니다. VMProtect 가상화의 MBA 표현식의 예는 아래와 같습니다.
(bvor
(bvnot (bvor (bvnot (bvnot x)) (bvnot y)))
(bvnot (bvor (bvnot x) (bvnot (bvand (bvnot y) (bvnot y)))))
)위 식은 단순한 x^y 연산과 동일하지만, 직관적으로 파악하기는 어렵죠?
이처럼 복잡하게 형성되어있는 표현식을 SSA 기반의 LLVM IR로 변환하면 데이터 흐름이 명확해지고, LLVM 최적화(Constant Propagation, Dead Code Elimination, Pattern Recognition 등)를 통해 불필요한 연산과 노이즈를 제거할 수 있습니다. 결과적으로 수만 개의 VMP 명령어가 수십 개의 SSA IR로 축약되면서 원본 연산에 가까운 형태를 복원할 수 있게 됩니다!
Devirtualization
이번 연구글에서는 정적 리프팅을 통해 VM 구조를 이해한 경험을 바탕으로, 동적 트레이싱 기반 해제 접근법을 참고했습니다. 또한 Jonathan Salwan의 VMProtect-devirtualization Project를 활용하여 동적 트레이싱 기반 해제를 진행했습니다.
- pure function
#include <stdint.h>
uint32_t f(uint32_t x) {
x ^= 0xA3C59AC3u;
x = (x << 7) | (x >> 25);
x += 0x9E3779B9u;
return x;
}실습 대상은 순수 함수(pure function)를 대상으로 하는데, 순수 함수란 같은 입력이면 항상 같은 출력을 내고, random, global, 변수, I/O 등에 의존하지 않습니다. 이러한 특성 덕분에 devirtualization에 적합합니다.
How It Works?
가상화된 코드의 실행 기록 (T’) =
원본 코드의 실행 기록 (T) + 가상 머신(VM) 명령어의 실행 기록 (VM(T))실행기록(Trace)은 프로그램이 실행될 때 CPU가 처리한 명령어들의 목록을 시간 순서대로 받아 적은 것이라고 보면 쉽습니다. 목표는 T’에서 VM(T)라는 노이즈를 제거하고 순수한 T를 복원하는 것이고, 동작 원리는 아래의 5단계 절차를 확인해봅시다.
Identify the virtualized function and its arguments
전체 프로그램 중 어떤 부분이 VMProtect로 보호되어 있는지, 그리고 보호된 함수가 어떤 인자를 받아서 처리하는지 찾아냅니다.
Generate a VMProtect Trace of the target
(단계 1)에서 찾아낸 보호된 함수를 실제로 실행시켜, 어떤 명령어들이 어떤 순서로 실행되는지(CPU가 처리하는 모든 명령어 목록) 전체 기록(trace)를 수집합니다.
Construct symbolic expressions to obtain the relation between inputs and output
(단계 2)에서 얻은 명령어 기록을 분석합니다. 실제 값 대신 변수(symbolic variable)을 사용해서, 프로그램이 내부적으로 어떤 계산을 하는지 수학 표현식으로 정리합니다.
Apply optimizations on symbolic expressions to avoid as much as possible instructions from the VM
(단계 3)에서 만든 수학 표현식을 간단하게 정의하고, 이 과정에서 VM을 실행시키기 위한 불필요한 명령어들에 해당되는 부분을 제거합니다.
Lift our symbolic representation to the LLVM-IR
(단계 4)에서 찾아낸 핵심 로직을 LLVM-IR(특정 CPU에 종속되지 않는 범용적인 코드 형태) 중간 단계 코드로 변환합니다. 이때 이 LLVM-IR을 다시 컴파일 하면, VMProtect 보호가 적용되지 않은 깨끗한 버전의 원본 프로그램을 최종적으로 만들어낼 수 있다고 합니다.
이 과정을 통해 최종적으로 VMProtect 난독화가 제거된 LLVM-IR을 얻을 수 있습니다.
Example: Bitwise Function
int bitwise_func(int a, int b, int flag) {
VMProtectBegin("bitwise_func");
int r;
if (flag == 0)
r = a & b;
else if (flag == 1)
r = a | b;
else
r = a ^ b;
VMProtectEnd();
return r;
}제공된 예제에서는 단순 산술 연산을 선정했지만 저는 control flow를 포함하는 코드를 빌드했습니다. 참고로 단순 연산 코드가 아닌 분기문을 포함한 함수를 분석하기 위해서는 trace를 여러 개 생성해야만 로직을 복원할 수 있습니다. LLCM-IR 모듈은 CFG(Control Flow Graph)를 가지고 있기 때문에, 각 분기문으로부터 얻은 trace들을 CFG로 병합하기 위해 추가적인 과정이 필요합니다.

VMProtect에서 가상화 옵션을 적용하기 전후 바이너리를 비교해보면 파일 크기가 어마어마하게 커지는 것을 볼 수 있습니다. 원본 코드가 VMProtect의 바이트코드로 변환되고, 이를 해석하고 실행하기 위한 가상머신(Interpreter)이 바이너리에 추가되었기 때문입니다. (여담이지만 이러한 크기 증가의 부담때문에 난독화할 때 해당 옵션을 적용하지 않는 경우도 드물지 않다고 하네요.. 하지만 그대신 난독화 효과는 강력했습니다.)
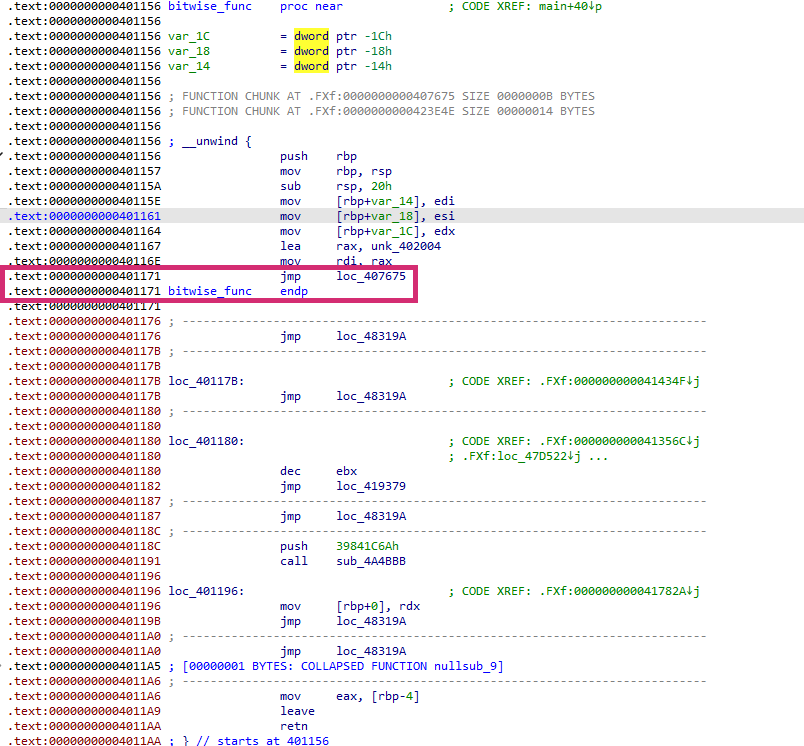
가상화 옵션이 적용된 bitwise.vmp.bin 파일을 확인해보면 몇 가지 특이한 점을 볼 수 있는데요. 저의 경우와 같이 기본적인 VMProtect 가상화 옵션 적용만으로 함수의 RVA가 변경되지 않습니다만, option에 따라 변경될 수도 있습니다. 또한 ret 없이 jmp를 통해 loc_407675로 점프되면서 원래 코드가 아닌, VMProtect 시작 지점으로 흐름이 넘어가는 모습이 가상화의 대표적인 특징으로 볼 수 있었습니다.
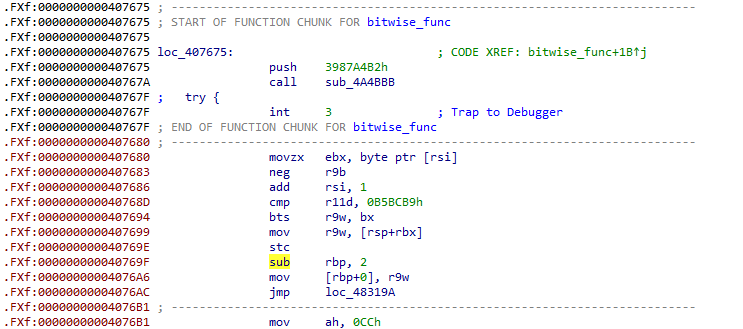
loc_407675로 들어가봅시다. 초기에 push 3987A4B2h, call sub_4A4BBB, int 3을 통해 스택에 3987A4B2h context 값을 넣고, sub_4A4BBB 함수를 호출하면서 인터프리터에 진입합니다.
이후 VmHandler라는 코드 블록을 수행하는데요. call 명령어로 진입한 루프 내부에서 VIP를 이용해 바이트코드를 읽어오고 HANDLER 위치를 찾아내 특정 연산을 수행하는 가상 명령어 처리 과정을 반복합니다.
Trace 수집 (Intel Pin)
📌Pin이란
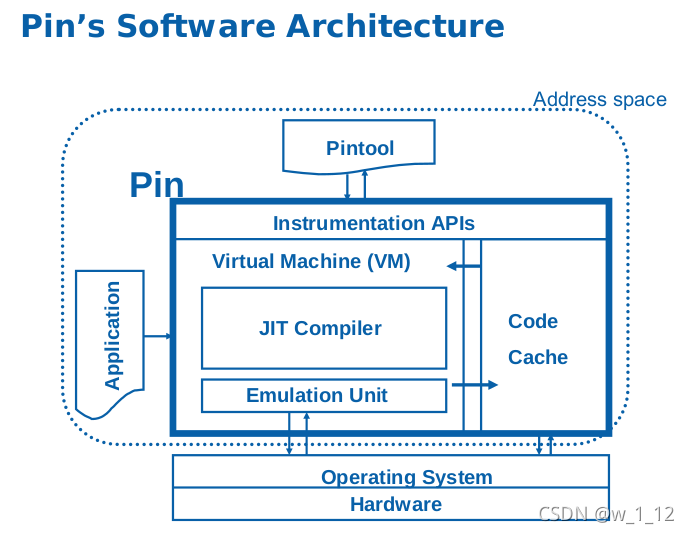
Pin은 Intel에서 제공하는 동적 바이너리 계측(DBI) 프레임워크로, Windows와 Linux 환경의 x86 및 x64 바이너리를 지원합니다. Pin은 프로그램을 직접 수정하지 않고 JIT(Just-In-Time) 기반 코드 변환을 통해 실행 흐름에 개입하며, 사용자가 작성한 pintool을 삽입해 명령어 실행, 메모리 접근, 함수 호출 등 런타임 동작을 관찰하고 기록할 수 있습니다.
이러한 Pin의 특성을 활용하면, JIT 단계에서 실행 흐름을 가로채 사용자 정의 pintool을 주입하고, 지정한 구간의 trace를 효과적으로 수집할 수 있습니다.
TRACE_AddInstrumentFunction(OnTrace, 0);
VOID OnTrace(TRACE t, VOID*) {
for (BBL b = TRACE_BblHead(t); BBL_Valid(b); b = BBL_Next(b)) {
for (INS i = BBL_InsHead(b); INS_Valid(i); i = INS_Next(i)) {
// 실제 훅 삽입
}
}
}
// 등록
TRACE_AddInstrumentFunction(OnTrace, 0);Pin의 동작은 다음과 같은 순서를 따릅니다.
- 프로그램이 실행될 때 Pin이 코드 블록(Trace) 실행을 가로챕니다.
- Pin은 해당 Trace를 즉시 실행하지 않고, 사용자가 등록한
콜백 함수(OnTrace)를 먼저 호출합니다. - OnTrace 내부에서 분석 코드를 삽입하거나, 원하는 명령어에 대해 hook을 추가할 수 있습니다. (일명 코드 끼워넣기)
- 원본 코드와 삽입된 분석 코드가 합쳐져 JIT 컴파일되며, 결과적으로 프로그램은 “원본 동작 + 기록 기능”을 동시에 수행합니다.
위 과정을 통해 Pin은 실행된 모든 기계어 명령어를 왜곡 없이 기록할 수 있게 됩니다.
./pin -t ./source/tools/VMP_Trace/obj-intel64/VMP_Trace.so \
-start 0x401156 -end 0x4011AA \
-- ./bitwise.vmp.bin 0 &> ./bitwise.vmp.traceTrace를 수집하기 위해서는 이전에 확인했던 정적 분석을 통해서 분석하고자 하는 함수의 start address(0x401156), end address(0x4011AA), 그리고 인자가 몇 개 들어가는지 정도 확인해주면 됩니다. 이 주소 범위를 바탕으로, Intel Pin 도구를 사용해 trace를 수집합니다.
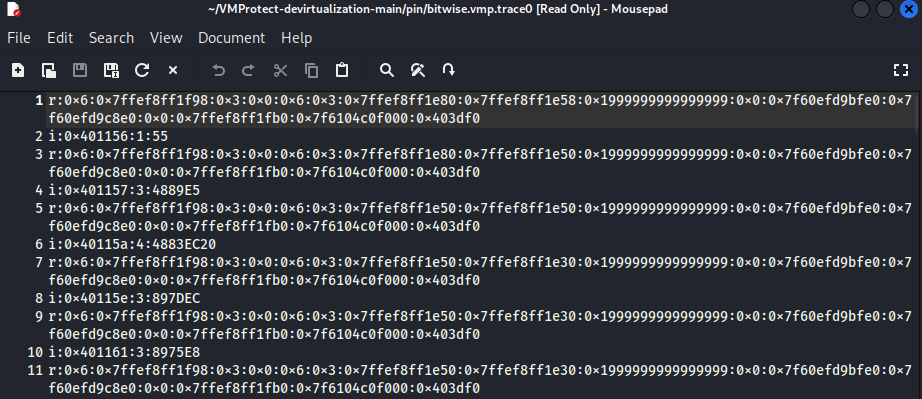
생성된 trace 파일 내부를 살펴보면, pin을 사용해 bitwise.vmp.bin을 flag=0 인자와 함께 실행했을 때, 지정한 범위 내에서 CPU가 실행한 모든 기계어 명령어 기록을 담고 있음을 확인할 수 있습니다. 파일 구조를 확인해보면 r:, i:를 한 쌍으로 기록하는 형식을 가지고 있습니다.
r:(Registers):i:가 실행되기 이전의 모든 CPU 범용 레지스터 상태를 16진수 값으로 기록한 형태를 담고 있습니다.i:(Instruction): 실제로 실행된 명령어 자체에 대한 정보이며,i:<명령어 주소>:<명령어 크기(byte)>:<기계어 코드(Opcode)>로 구성되어 있습니다. 예를들면i:0x401156:1:55는0x401156이라는 시작 주소를 정확하게 담고있고, ‘0x55(push rbp) 명령어를 실행했다’는 방식으로 해석할 수 있습니다!
하지만 생성된 trace 파일은 인간이 전부 읽기에는 방대하기 때문에 불가능에 가깝습니다.. attack_vmp.py 같은 도구를 사용해 원본 로직을 담은 LLVM-IR을 생성해봅시다.
vbraddr(Virtual Branch Address) 구하기
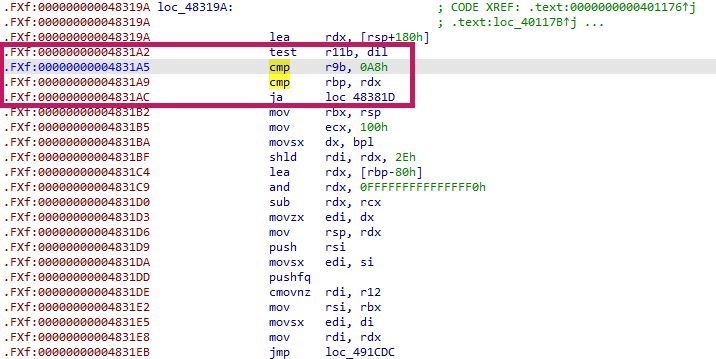
저의 경우와 같이 분기문을 포함한 함수의 전체 로직을 복원하기 위해서는, 서로 다른 실행 경로를 담고 있는 여러 개의 Trace 파일을 동시에 분석해야 합니다. 그런데 VMProtect는 일반적인 jmp, jz, jnz 같은 직접적인 분기 명령어를 사용하지 않고 가상화된 분리 로직을 사용합니다. 이 경우 attack 스크립트는 이 경로들이 정확히 어느 지점에서 갈라졌는지 자동으로 파악하기 어렵습니다.
이 vbraddr 주소 값을 인간이 IDA로 찾아서 넣어주도록 합시다. trace 상에서 cmp나 test 같은 비교 명령어가 위치한 부분 중 가상 분기를 결정하는 부분을 정확히 찾아주면 됩니다. 필자의 경우에는 0x4831A5가 가상 분기 주소에 해당했습니다. 그리고 이 vbraddr이 후에 CFG가 갈라지는 기준점을 명시하는 역할이 되어줍니다.
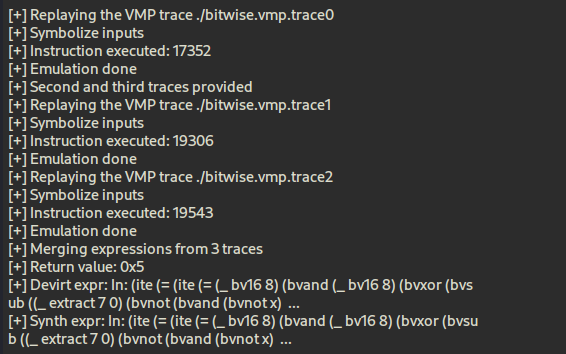
attack_vmp.py 스크립트의 동작 방식을 살펴봅시다. 해당 스크립트는 Triton 프레임워크를 기반으로 동작합니다.
- Triton은 Trace 내의 실행된 명령어를 하나씩 해석하면서 레지스터와 메모리를 심볼릭 변수(symbolic variable)로 추적합니다.
- 이 과정에서 레지스터와 메모리 상태가 AST(Abstract Syntax Tree) 형태로 관리됩니다.
- Triton의 symbolic execution 엔진을 통해 path predicate를 구축하여 조건 분기까지 수학적으로 모델링합니다.
- 이를 통해 VMProtect 노이즈가 구체화(concretization) 단계에서 자동으로 상수 처리되어 제거되고, simplification pass와 formula slicing 기능을 활용해 최종적으로 표현식을 입력과 출력 관계만 담은 수학 표현식으로 단순화 하는 원리입니다.
./attack_vmp.py \
--trace1 ./bitwise.vmp.trace0 \
--trace2 ./bitwise.vmp.trace1 \
--trace3 ./bitwise.vmp.trace2 \
--symsize 4 \
--vbraddr 0x4831a5 \
--vbrflag af스크립트 명령어로 각각 다른 분기문을 타는 trace 세 개 파일을 넣어주고, —vbraddr과 —vbrflag 옵션을 함께 전달해줍시다. 참고로 기존에 제공된 attack_vmp 스크립트는 trace를 두 개까지 밖에 못 줘서 trace 파일을 더 많이 줬을 때 이를 연결지어 LLVM-IR로 결합할 수 있는 스크립트 기능으로 조금 확장해봤습니다. 과연 세 개의 분기문을 병합해 CFG 형식으로 복원할 수 있을까요?
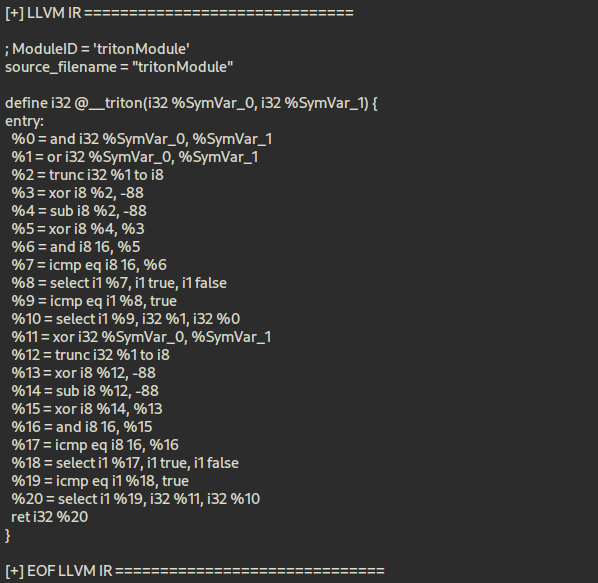
생성된 LLVM-IR을 확인해보면 원본 코드의 if-else 구조와 비트 연산(XOR, AND, OR) 조합을 정확하게 구현했다는 점을 알 수 있습니다. (LLVM-IR Language가 궁금하다면 이 곳에서 확인할 수 있습니다.)
LLCM IR 리프팅 결과, %SymVar_0, %SymVar_1에 대해 처음에는 AND와 OR 연산이, 그 다음에 XOR 연산이 각각 조건 검사를 거쳐 결과를 선택한다는 점을 확인할 수 있었습니다. -88, ==16 같은 불필요한 비교는 VMProtect 가상화 과정에서 삽입된 노이즈이지만, 핵심 로직과 무관합니다.
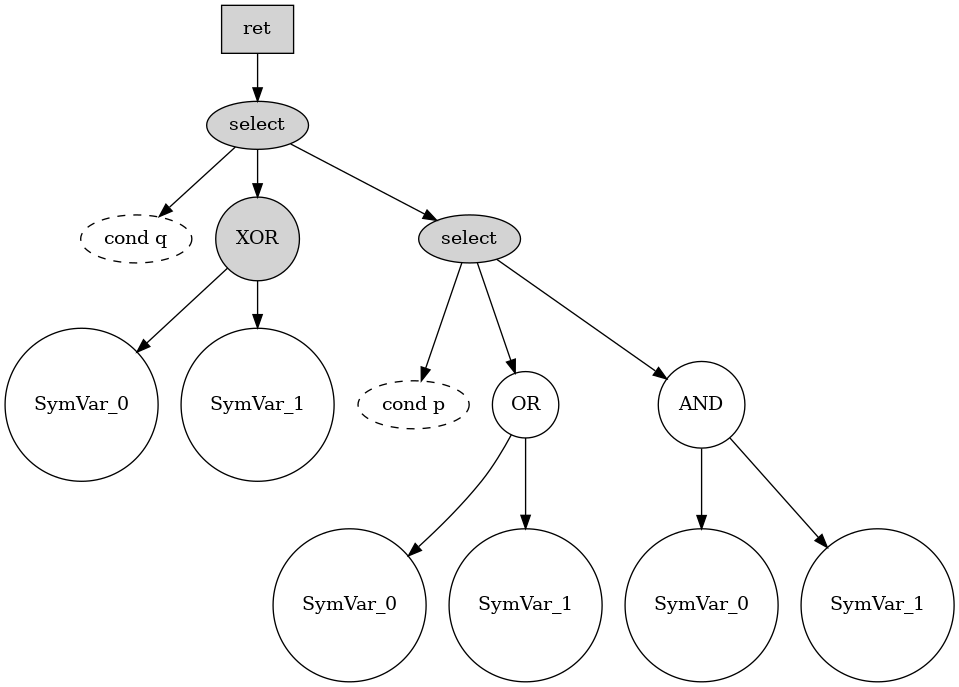
위 그래프는 VMProtect로 가상화된 함수를 devirtualization 과정에서 복원한 결과로, 함수의 반환 값이 select 연산에 의해 결정되는 구조를 보여줍니다. 첫 번째 select 노드는 cond q라는 조건에 따라 왼쪽으로는 SymVar_0과 SymVar_1을 XOR한 결과를, 오른쪽으로는 또 다른 select 노드의 결과를 선택하고 있습니다. 오른쪽의 select 노드는 cond p 조건에 따라 참일 경우 SymVar_0과 SymVar_1을 OR한 결과를, 거짓일 경우 SymVar_0과 SymVar_1을 AND한 결과를 선택합니다.
Conclusion
사실 이번 글에서 다룬 LLVM 기반의 devirtualization 접근법은 단일 경로나 소수의 실행 경로를 가진 함수에서는 효과적이지만, 경로 수가 많은 프로그램에서는 일부 코드가 누락될 수 있기 때문에 현실적인 규모의 코드에 해당 접근법을 적용하기에는 아직 무리가 있었습니다. 따라서 이번 연구글은 여기서 part 1을 마무리하려고 합니다.
다음 part에서는 관련 논문들을 기반으로 정적 분석을 중점에 두어 devirtualization 가능성을 담아보고, virtualization 뿐만이 아닌 다양한 options에 대한 난독화 해제 접근법을 살펴보겠습니다! 감사합니다.
Reference
https://koreascience.kr/article/JAKO202106153172639.pub?&lang=ko
https://github.com/JonathanSalwan/VMProtect-devirtualization/tree/main

본 글은 CC BY-SA 4.0 라이선스로 배포됩니다. 공유 또는 변경 시 반드시 출처를 남겨주시기 바랍니다.