[Research] LLM Security & Safety Part 3. “Attention Is All You Need for LLM-based Code Vulnerability Localization” Review (KR)
1. 서론
오랜만에 또 논문 리뷰로 돌아온 j0ker입니다! 원래 팀에는 “이번 Usenix 논문들 전체를 LLM으로 분석해서 트랜드 분석을 해볼거야!”라고 했지만… 네… 어림도 없었죠? 역시 현생은 만만치 않습니다.

노예는…. 언제쯤 행복할 수 있을까…?
그래서 이번에도 논문 한편을 가져와 봤습니다. 저번 논문은 “아 누구나 생각할 법한걸 했네”라고 생각이 들었다면 이번에는 “오 얘는 좀 다르군”이라는 생각이 바로 들었던 논문입니다. 다른 논문들은 프롬프팅, RAG 등을 통해 LLM의 추론 아웃풋에 집중했다면 이 논문은 LLM의 구조 자체를 활용한다는 점에서 눈에 띄었습니다.
바로 2024년 10월에 Arxiv에 공개된 “Attention Is All You Need for LLM-based Code Vulnerability Localization” 입니다. 따로 어느 학회에 투고하지는 않고 아카이브에만 올린것 같은데요. 아이디어 자체는 괜찮지만 아마 결론 부분이 좀 아쉽지 않나 싶습니다.
2. 논문 리뷰
“Attention Is All You Need for LLM-based Code Vulnerability Localization”라는 이름에서 알 수 있다시피 이 논문에서는 LLM의 self-attention 메커니즘을 활용해 취약점 위치를 파악할 수 있다는 것이 주요 골자입니다. “Attention Is All You Need”라는 현재 LLM의 기반이 되는 논문을 오마주했다는 것도 매우 재미있는 포인트입니다 ㅋㅋ
2.1 기존 방법들의 한계
1) Lost in the Middle
본격적으로 내용에 들어가기 전, 논문에서 지적하는 LLM이 취약점 탐지에서 가지는 가장 큰 한계점은 “긴 컨텍스트에서의 추론 정확도 감소”입니다. 코드가 300줄이 넘어가기 시작하면 정확도는 5% 미만으로 내려간다고 합니다.
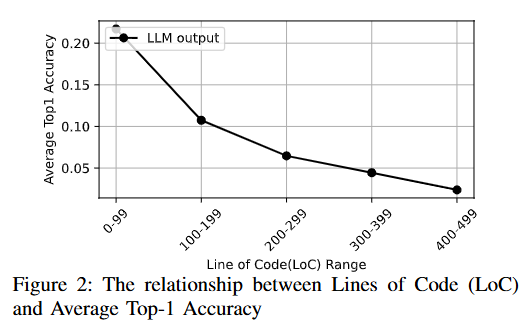
또한 근거로 제시한 논문들은 다음과 같습니다.
- Lost in the Middle: How Language Models Use Long Contexs
- BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
하지만 다들 이 글을 읽으면서 또 논문을 읽고 싶지는 않으시겠죠? 한 유튜브 채널에서 유사한 주제를 다룬 영상이 있어 이걸 보셔도 좋겠습니다.
위 내용들을 자세히 읽어보지는 않았지만 핵심 내용과 관련없는 토큰이 많아짐에 따라 어텐션해야 할 내용들에 정확히 어텐션하지 못하거나 하는 등의 문제일 것입니다. 이 문제는 LLM 서비스들을 많이 써보시고, 특히 취약점 탐색을 위해 긴 코드들을 넣어보신 분들이라면 다들 한 번씩은 겪어보셨을 문제일 겁니다. 여러 함수에 걸쳐 취약점을 찾아달라고 하면 코드를 까먹거나 기억을 못한다거나 하는 문제들이 발생합니다. 하지만 이러한 문제들은 (체감적으로)작년 말 ~ 올해 초부터 많이 나아지고 있다는 것을 느끼기도 합니다. 그리고 이런 문제들을 개선할 수 있는 논문들도 나오고 있습니다.
(여기는 LLM이 찾아준 정보입니다 ㅋㅋ)
- 위치에 상관없이 정보를 찾는 훈련 방식
- “Never Lost in the Middle: Mastering Long-Context Question Answering with Position-Agnostic Decompositional Training” (2024)
- 핵심 내용: 이 문제를 해결하기 위해 ‘위치에 구애받지 않는 분해 훈련(Position-Agnostic Decompositional Training)’ 이라는 새로운 훈련 방법을 제안합니다. 긴 질문을 여러 단계의 짧은 질문으로 분해하고, 정답의 위치를 의도적으로 다양하게 섞어서 모델을 훈련시킵니다.
- 해결 방식: 모델이 정보의 ‘위치’에 의존하는 편향을 줄이고, 문맥 어디에 있든 필요한 정보를 찾아내는 능력을 강화시킵니다.
- “Never Lost in the Middle: Mastering Long-Context Question Answering with Position-Agnostic Decompositional Training” (2024)
- 입력 데이터의 구조 변경
- “Structured Packing in LLM Training Improves Long Context Utilization” (2023)
- 핵심 내용: 여러 문서를 단순히 순서대로 이어 붙여 훈련시키는 대신, 관련 있는 정보를 구조적으로 묶어서(packing) 모델에 제공하는 방식을 제안합니다.
- 해결 방식: 정보의 논리적 연결성을 강화하여 모델이 문맥 중간에 있는 정보라도 그 중요성을 더 잘 파악하고 활용하도록 돕습니다.
- “Structured Packing in LLM Training Improves Long Context Utilization” (2023)
- 어텐션 메커니즘 개선
- “Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation” (2025)
- 핵심 내용: 모든 토큰을 동일하게 처리하는 대신 ‘라우터’를 통해 중요한 토큰을 식별하고, 해당 토큰에 더 많은 연산을 동적으로 할당하는 MoR(Mixture-of-Recursions) 아키텍처를 제안합니다.
- 해결 방식: 정보의 위치가 아닌 중요도에 따라 컴퓨팅 자원을 집중하여, 문맥 중간에 있는 핵심 정보도 놓치지 않고 깊이 있게 처리합니다.
- “Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation” (2025)
- 검색 증강 생성(RAG)과의 결합 및 비교
- “Long Context vs. RAG for LLMs: An Evaluation and Revisits” (2025)
- 핵심 내용: 긴 문맥을 통째로 입력하는 방식(Long Context)과 외부 데이터베이스에서 필요한 정보만 검색해서 제공하는 RAG(Retrieval-Augmented Generation) 방식을 비교 분석합니다.
- 해결 방식: RAG는 애초에 필요한 정보만 ‘검색’해서 문맥의 앞부분에 제시하므로, “Lost in the Middle” 문제를 원천적으로 회피하는 효과적인 대안이 될 수 있음을 보여줍니다. 다만, 어떤 방식이 더 우월한지는 태스크의 종류에 따라 달라진다고 분석합니다.
- “Long Context vs. RAG for LLMs: An Evaluation and Revisits” (2025)
위 논문들을 보면 훈련 과정, 훈련 데이터셋, 어텐션 메커니즘, 컨텍스트 등 다양한 방면에서 이 문제를 해결하기 위해 연구를 하고 있는 것을 알 수 있습니다.
2) 정확도
LLM의 근본적인 문제점인 출력 결과의 정확도 입니다. 물론 처음 ChatGPT 3.5가 공개되었을 때보다는 훨씬 나아졌지만 여전히 오탐과 미탐 문제는 존재합니다. 이를 해결하기 위해 다음과 같은 고급 reasoning 기법들이 사용되었습니다.
- SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
- MUTUAL REASONING MAKES SMALLER LLMS STRONGER PROBLEM-SOLVERS
하지만 이런 고급 프롬프팅, CoT 기법들도 모두 stochastic decoding에 의지해 여러 출력을 활용해 다수결 투표를 하거나 점수를 매기는 등 불완전한 방법이라고 합니다.
- Stochastic decoding(확률적 디코딩)은 LLM이 텍스트를 생성할 때 다음 토큰을 선택하는 방식 중 하나로 계산된 확률 분포에서 무작위로 토큰을 샘플링합니다. 즉, 확률이 가장 높은 토큰을 ‘항상’ 선택하는 것이 아니라, 각 토큰의 확률에 비례하여 선택될 기회를 주는 것입니다.
- 반대로 Deterministic Decoding(결정론적 디코딩)은 단순히 확률이 가장 높은 토큰을 선택하는 것으로 매번 동일한 입력에 대해 동일한 출력을 보장하지만, 반복적이고 덜 창의적인 결과를 생성할 수 있습니다.
“이러한 무작위성으로 인해 결과의 정확도 향상도 미미하고 취약점이 존재하는 정확한 위치를 찾아내기가 힘들다!”가 이 논문에서 제시하는 두 번째 문제점입니다.
2.2 가설 및 실험
1) 가설
- 취약한 코드를 찾을 때 특정 라인에 어텐션을 하게 된다.
- 특정 라인에서 찾으라고 하면 어텐션이 더 강하게 되서 정확도를 올릴 수 있다.
- 취약점이 존재하는 라인은 모델 출력에 영향을 미칠 것이다.
- 취약점이 존재하지 않은 라인을 하이라이팅해도 결과에 영향을 주지 않을 것이다.
2) 실험
논문에서는 self-attention을 활용해 취약점의 위치를 파악할 수 있는지 먼저 테스트를 진행합니다.
Code:
....
8: glyphs = (cairo_glyph_t *) gmalloc (len
* sizeof (cairo_glyph_t));
9: glyphCount = 0;
10: }
Pay attention to line {8}. Check whether there are vulnerabilities in it.
vulnerable line: ```취약점을 찾기 위해 위와 같이 프롬프트를 작성하면 ``` 뒤에 단어를 예측할 때 취약점이 있는 코드를 가장 높게 어텐션하겠죠? 뿐만 아니라 어떤 라인인지 까지 알려줘서 가중치의 변화를 극대화해 변화를 관찰합니다.
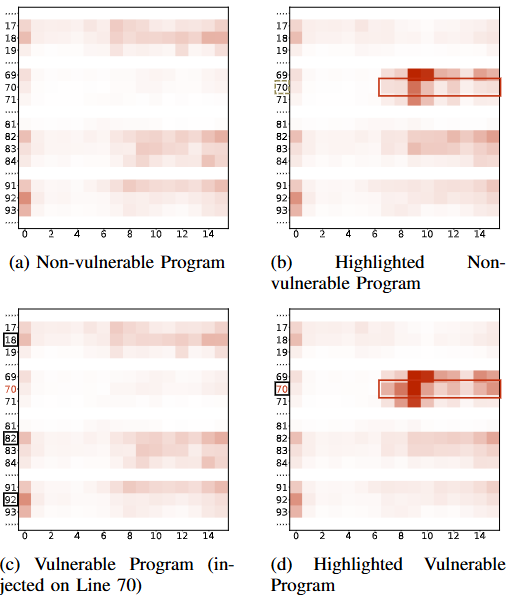
실제 취약점이 없는 코드와 이를 베이스로 코드에 취약점을 인위적으로 삽입해 테스트를 진행한 결과,
- 취약점이 없는 코드와 있는 코드의 어텐션을 확인한 결과 취약점이 존재하는 70번째 라인을 제외하고 다른 라인들의 가중치가 높은 것으로 나와 제대로 취약점을 식별하지 못하는 것으로 나타났습니다.
- 취약점이 없는 코드와 있는 코드에 70번째 라인에 취약점이 있는지 하이라이트해서 어텐션을 확인한 결과 70번째 라인이 좀 더 가중치가 올라갔고 실제 취약점이 있는 코드에서는 가중치가 더 높게 나타났습니다.
위와 같이 간단한 테스트를 통해 취약점을 어느정도 식별할 수 있다는 것을 확인할 수 있습니다.
3. LOVA(LO-cating Vulnerabilities via Attention)
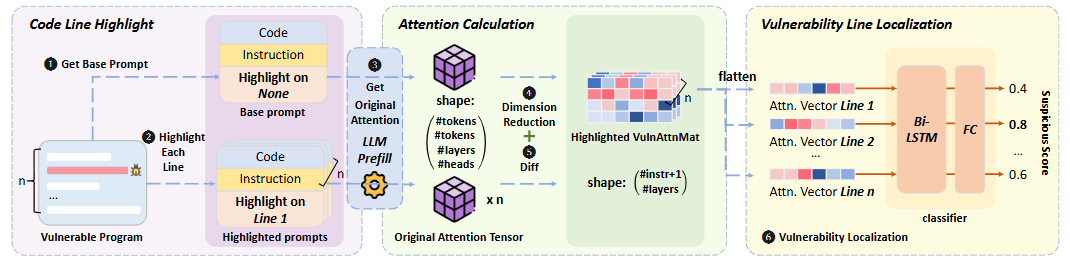
이 논문에서 제안하는 LOVA는 위에서 실험한 내용을 바탕으로 하이라이팅하지 않은 코드와 하이라이팅한 코드의 가중치를 비교해 최종적으로 취약점이 존재할 확률이 가장 높은 코드 라인을 찾아냅니다.
크게 Code Line Highlight, Attention Calculation, Vulnerability Line Localization 3단계로 나뉩니다. 하나씩 차근차근 뜯어보죠!
3.1 Code Line Highlight
LOVA는 두 가지 버전의 프롬프트를 만듭니다. 하나는 아무것도 건드리지 않은 원본 코드(Base prompt), 다른 하나는 코드 한 줄 한 줄을 돌아가면서 강조한 버전(Highlighted prompts)입니다. 만약 코드가 100줄이라면, 1개의 원본 프롬프트와 100개의 하이라이트된 프롬프트가 생성되는 것이죠.
하지만 여기서 문제가 하나 있습니다. 그냥 주석으로 // 여기 좀 봐줘! 라고 하거나 특정 키워드를 넣는 방식은 코드가 길어지면 LLM이 그냥 무시해버리거나, 오히려 hallucination이 발생해 멀쩡한 코드를 취약하다고 착각한다고 합니다.
따라서 LOVA에서는 코드 라인 인덱스를 직접 지정합니다. 코드 앞에 번호를 쫙 붙여주고, 프롬프트에 ‘8번 라인에 집중해서 취약점이 있는지 봐줘!’ 라고 명시하는 겁니다.
3.2 Attention Calculation
다음은 각 라인을 하이라이팅했을 때 LLM의 ‘관심도(Attention)’가 얼마나 변하는지 정량적으로 계산할 차례입니다. LLM이 뱉어내는 어텐션 데이터는 (num_tokens, num_tokens, num_layers, num_heads) 형태의 어마어마하게 큰 텐서(Tensor)입니다. 논문에서는 1000토큰짜리 코드만 해도 데이터가 수억 개가 될 수 있다는데… 그럼 제가 직접 분석하는게 더 빠르겠죠?
LOVA는 이 거대한 데이터를 ‘취약점 분석에 필요한 정보만’ 남기도록 다음과 같이 차원 축소(Dimensionality Reduction)를 진행합니다.

Step 1 ~ 4까지의 슈도코드
- 모든 헤드의 어텐션을 (num_tokens, num_tokens, num_layers) 형태의 하나의 어텐션 맵으로 합산한 뒤 병합합니다.
- 각 레이어의 어텐션은 서로 고유의 의미를 가지고 있기 때문에 유지합니다.
- 마지막 토큰을 쿼리(Q)로 사용하여 이전의 모든 토큰에서 얼마나 많은 어텐션을 가지는지 확인하고 (num_tokens, num_layers) 크기의 행렬을 생성합니다.
- 각 라인의 모든 토큰의 어텐션 값을 합산하여 한 라인의 전체 어텐션 값을 계산하여 (num_lines, num_layers) 크기의 행렬을 생성합니다. 여기서 이 행렬을 LayerwiseAttnMat라고 부릅니다.
강조 표시된 프롬프트의 LayerwiseAttnMat와 기본 프롬프트 간의 차이를 계산하여 DiffAttnMat를 생성합니다. 모든 라인의 차이를 보는 게 아니라, 실제 변화가 가장 클 것으로 예상되는 ‘지시문’과 ‘하이라이트된 라인’의 데이터만 뽑아와 최종적인
VulnAttnMat을 만듭니다.
3.3 Vulnerability Line Localization
마지막 단계는 VulnAttnMat의 패턴을 보고 진짜 취약점이 있는 라인을 골라내는 것입니다. 단순히 어텐션 변화량 합계로 순위를 매길 수도 있지만, C언어의 취약점 패턴과 파이썬의 취약점 패턴이 다르기 때문에 언어별로 일관된 기준을 적용하기 어렵습니다. 또, 이건 그냥 ‘의심 순위’일 뿐, ‘이 라인이 취약할 확률이 80%다!’ 와 같은 정확한 판단을 내려주진 못하죠. 그래서 LOVA는 이 단계에서 Bi-LSTM이라는 딥러닝 모델을 사용합니다.(으으… 점점더 복잡해지는…)
- 먼저 각 라인별로 계산된
VulnAttnMat을 길게 편 벡터로 만듭니다. - 이 벡터 시퀀스를 Bi-LSTM 모델에 입력으로 넣어줍니다. Bi-LSTM을 쓰는 이유는 특정 라인(A)이 의심스러운지 판단할 때, 그 앞뒤 라인(B, C)들의 어텐션 패턴과 비교해서 판단하는 것이 더 정확하기 때문입니다. 즉, 전체 코드의 문맥(Context)을 양방향으로 고려하는 거죠.
- 모델은 최종적으로 각 라인에 대해 0과 1 사이의 ‘의심 점수(Suspicious Score)’를 출력하고, 이 점수가 0.5를 넘으면 취약한 코드라고 판단하게 됩니다.
4. 결과
테스트는 Big-Vul, SmartFix, CVEFixes 벤치마크를 대상으로 했으며 Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.2, Phi3.5-mini-instruct 같이 10B 이하의 모델들을 활용했다고 합니다.
- LOVA는 기존 LLM의 직접 출력 방식에 비해 뛰어난 취약점 위치 특정 능력을 보여주며, 특히 긴 코드 맥락에서 F1-score 기준으로 최대 5배의 성능 향상을 달성했습니다.
- LOVA는 다양한 프로그래밍 언어에서 뛰어난 취약점 위치 특정 결과를 달성하며, 최대 14.6배의 향상을 보였습니다.
- LOVA는 다양한 LLM 아키텍처에 적용 가능하며 일관된 결과를 보여줍니다.
전체적으로 인상적인 성능을 보여줍니다. 모두 같은 모델을 활용한다고 했을 때, CoT, MoA, rStar 등 여러 기법을 사용한 것과 비교한 것도 좋았습니다. 무엇보다 self-attention 메커니즘을 처음으로 취약점 탐지에 사용했다는 시도만으로도 의미가 있다고 생각합니다.
5. 아쉬운 점
- 더 큰 모델과의 비교 부재
- 이 논문에서는 Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.2, Phi3.5-mini-instruct를 사용해 테스트를 했지만 이보다 큰 모델과의 비교가 없습니다.
- 이 논문에서의 방식을 사용하기 위해서는 각 코드 라인마다 어텐션 메트릭스를 만들어야 하는데, 이 때 걸리는 시간이나 연산해야할 행렬이 더 많아져 큰 모델을 활용하기에는 하드웨어가 부족했다고 생각하긴 합니다.
- 그렇다면 더 큰모델의 바닐라 아웃풋과의 비교정도는 해봐도 좋지 않을까 싶네요.(아 이건 내가 해보면 되나…?) 더 큰 모델의 바닐라 아웃풋과 비빌만하다…! 정도로만 나와도 의미있으려나…?
- 전력 효율성 또는 계산 비용 비교 부재
- LOVA는 각 코드 라인을 개별적으로 하이라이트하여 여러 버전의 프롬프트를 생성하고, 이들 간의 어텐션 맵 차이를 계산하는 등 여러 단계를 거칩니다. 또한 차원 축소 및 Bi-LSTM 분류기 사용은 복잡도를 더할 수 있습니다.
- 이 논문은 실제 대규모 소프트웨어 프로젝트에 적용될 때 발생하는 시간적, 재정적 비용에 대한 언급이 부족합니다. 데이터셋 비교는 성능 비교 차원에서 활용하는 것은 좋지만 코드양이 늘어났을 때 얼마나 더 많은 계산을 해야하는지 측정하는 내용이 있었으면 좋을것 같습니다.(논문은 LLM의 입력 제약사항을 준수하기 위해 4,000 토큰을 초과하는 컨텍스트를 필터링했다고 언급합니다.)
후… 이번 포스팅은 이정도로 마무리하겠습니다. 직접 개발해서 2편으로 만들까…?라는 생각을 해보았지만… 제 현생이 저한테 허락해주지 않을거 같습니다. 하하 그렇다면 다음 편으로 돌아오겠습니다! (이제는 진짜 Usenix 봐야지…)

본 글은 CC BY-SA 4.0 라이선스로 배포됩니다. 공유 또는 변경 시 반드시 출처를 남겨주시기 바랍니다.