[Research] LLM Security & Safety Part 3. “Attention Is All You Need for LLM-based Code Vulnerability Localization” Review (EN)
1. Introduction
It’s been a while since my last post, but I’m back! I originally told my team, “I’m going to analyze all of the Usenix papers using LLM and analyze the trends!” But… well… that was wishful thinking, wasn’t it? As expected, real life is not going so easy.

When will slaves be able to be happy?
So, I brought another paper this time. If you thought, “Oh, this is something anyone would think of” about the previous paper, this paper immediately made me think, “Oh, this one is a little different.” While other papers focused on the inference output of LLM through prompting, RAG, etc., this paper stood out in that it utilized the structure of LLM itself.
It is “Attention Is All You Need for LLM-based Code Vulnerability Localization,” which was published on Arxiv in October 2024. It seems that it was not submitted to any academic conference but only uploaded to the archive. The idea itself is good, but I think the conclusion part is a little disappointing.
2. Paper Review
As the title “Attention Is All You Need for LLM-based Code Vulnerability Localization” suggests, this paper focuses on how the self-attention mechanism of LLM can be used to identify vulnerability locations. It is also an interesting point that the paper pays homage to “Attention Is All You Need,” which serves as the foundation for current LLMs. 😄
2.1 Limitations of Existing Methods
1) Lost in the Middle
Before delving into the details, the paper points out that the biggest limitation of LLM in vulnerability detection is the “decrease in inference accuracy in long contexts.” It is said that when the code exceeds 300 lines, the accuracy drops below 5%.
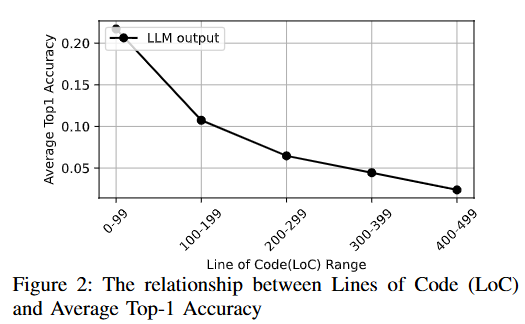
The papers cited as evidence are as follows.
- Lost in the Middle: How Language Models Use Long Contexs
- BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack
However, you probably don’t want to read all these papers while reading this article, right? There is a YouTube channel that covers a similar topic, so you may want to check it out.
I haven’t read the above content in detail, but it seems to be an issue where, as the number of tokens unrelated to the core content increases, the model fails to accurately focus on the content that requires attention. This is a problem that anyone who has used LLM services extensively, especially those who have tested them with long code snippets for vulnerability detection, has likely encountered at least once. When asking to identify vulnerabilities across multiple functions, issues such as forgetting or failing to recall the code may arise. However, I have noticed that these issues have improved significantly since late last year to early this year. Additionally, papers addressing these issues are beginning to emerge.
(This information was found by LLM. lol)
- Training method for finding information regardless of location
- “Never Lost in the Middle: Mastering Long-Context Question Answering with Position-Agnostic Decompositional Training” (2024)
- Key points: To address this issue, we propose a new training method called “Position-Agnostic Decompositional Training.” Long questions are decomposed into multiple short questions, and the positions of the correct answers are intentionally mixed to train the model.
- Solution: This reduces the model’s reliance on the ‘location’ of information and enhances its ability to find the necessary information regardless of context.
- Changing the structure of input data
- “Structured Packing in LLM Training Improves Long Context Utilization” (2023)
- Key points: Instead of simply concatenating multiple documents in order for training, this method proposes providing the model with information that is structurally grouped (packing) together.
- Solution: Strengthens the logical connectivity of information to help the model better understand and utilize information in the middle of the context.
- Improving the attention mechanism
- “Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation” (2025)
- Key Points: Instead of treating all tokens equally, we propose the MoR (Mixture-of-Recursions) architecture, which identifies important tokens through a “router” and dynamically allocates more computations to those tokens.
- Solution: By focusing computational resources on importance rather than location, we ensure that even core information in the middle of the context is processed deeply without being overlooked.
- Combination and Comparison with Retrieval-Augmented Generation (RAG)
- “Long Context vs. RAG for LLMs: An Evaluation and Revisits” (2025)
- Key Points: This paper compares and analyzes the “Long Context” approach, which inputs the entire long context, and the RAG (Retrieval-Augmented Generation) approach, which retrieves only the necessary information from an external database.
- Solution: RAG demonstrates that it can be an effective alternative to avoid the “Lost in the Middle” problem by initially “searching” for only the necessary information and presenting it at the beginning of the context. However, the analysis concludes that which method is superior depends on the type of task.
Looking at the above papers, we can see that research is being conducted to solve this problem in various aspects, such as training processes, training datasets, attention mechanisms, and context.
2) Accuracy
The fundamental problem with LLM is the accuracy of the output results. Of course, it has improved significantly since ChatGPT 3.5 was first released, but false positives and false negatives still exist. To address this, the following advanced reasoning techniques have been employed:
- SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
- MUTUAL REASONING MAKES SMALLER LLMS STRONGER PROBLEM-SOLVERS
However, even these advanced prompting and CoT techniques rely on stochastic decoding to utilize multiple outputs for majority voting or scoring, which are considered incomplete methods.
- Stochastic decoding is one of the ways LLMs generate text, where tokens are randomly sampled from a calculated probability distribution. In other words, it does not always select the token with the highest probability but gives each token a chance to be selected proportional to its probability.
- Conversely, deterministic decoding simply selects the token with the highest probability, ensuring the same output for the same input every time, but it can generate repetitive and less creative results.
“Due to this randomness, improvements in accuracy are minimal, and it is difficult to pinpoint the exact location of vulnerabilities!” This is the second issue raised in this paper.
2.2 Hypotheses and Experiments
1) Hypotheses
When searching for vulnerable code, attention is focused on specific lines.
If instructed to search for vulnerabilities on specific lines, attention becomes stronger, potentially improving accuracy.
Lines containing vulnerabilities will influence the model’s output.
Highlighting lines without vulnerabilities will not affect the results.
2) Experiment
The paper first tests whether self-attention can be used to identify the location of vulnerabilities.
Code:
....
8: glyphs = (cairo_glyph_t *) gmalloc (len
* sizeof (cairo_glyph_t));
9: glyphCount = 0;
10: }
Pay attention to line {8}. Check whether there are vulnerabilities in it.
vulnerable line: ```To find vulnerabilities, write a prompt as shown above. When predicting words after ```, the code with vulnerabilities will receive the highest attention, right? Not only that, but it also tells you which line it is, maximizing the change in weight and allowing you to observe the change.
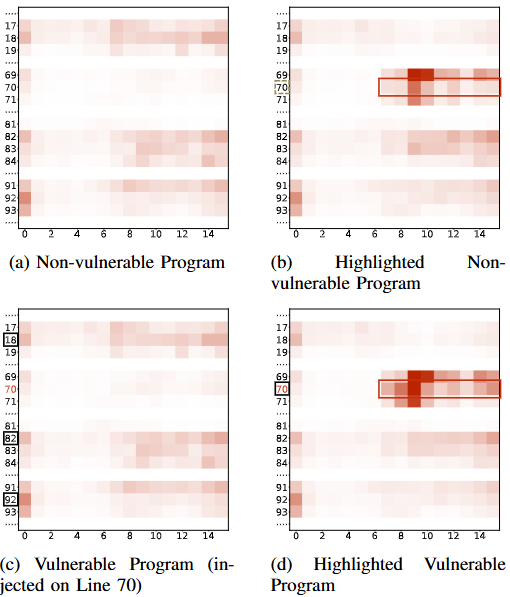
When testing with actual code without vulnerabilities and code with artificially inserted vulnerabilities based on the former,
- Upon checking the attention of code with and without vulnerabilities, it was found that, except for the 70th line where the vulnerability exists, the weights of other lines were high, indicating that the vulnerability was not properly identified.
- When highlighting the 70th line to check the attention in both the code without vulnerabilities and the code with vulnerabilities, the weight of the 70th line increased slightly, and in the code with actual vulnerabilities, the weight was even higher.
As shown above, this simple test demonstrates that vulnerabilities can be identified to some extent.
3. LOVA(LO-cating Vulnerabilities via Attention)
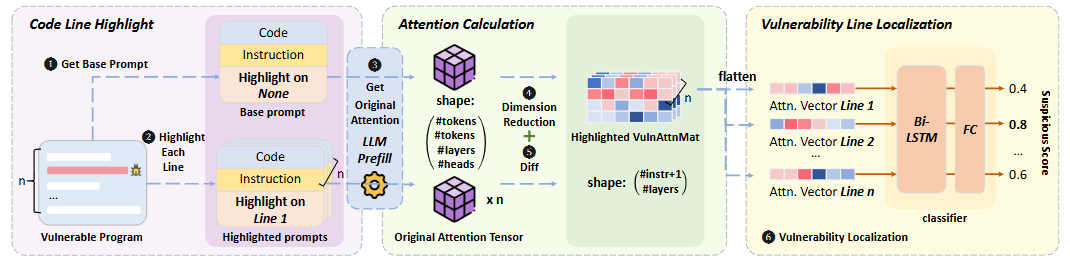
The LOVA proposed in this paper compares the weights of unhighlighted code and highlighted code based on the results of the experiments described above to ultimately identify the code lines with the highest probability of containing vulnerabilities.
It is divided into three stages: Code Line Highlight, Attention Calculation, and Vulnerability Line Localization. Let’s take a closer look at each one!
3.1 Code Line Highlight
LOVA creates two versions of prompts. One is the original code with no modifications (Base prompt), and the other is a version where each line of code is highlighted one by one (Highlighted prompts). If the code has 100 lines, one original prompt and 100 highlighted prompts are generated.
However, there is one problem here. Simply adding a comment like “// Take a look here!” or inserting specific keywords causes the LLM to ignore the code when it becomes long, or even causes hallucinations, mistaking normal code for vulnerable code.
Therefore, in LOVA, we directly specify the code line index. We add numbers to the front of the code and explicitly state in the prompt, “Focus on line 8 and check for vulnerabilities!”
3.2 Attention Calculation
Next, we need to quantitatively calculate how the LLM’s ‘attention’ changes when each line is highlighted. The attention data output by the LLM is an enormous tensor in the form of (num_tokens, num_tokens, num_layers, num_heads). The paper mentions that even a 1,000-token code can generate hundreds of millions of data points… So, analyzing it myself might be faster, right?
LOVA performs dimensionality reduction as follows to retain only the information necessary for vulnerability analysis from this massive dataset.

Pseudocode for Steps 1 to 4
- Summarize the attention of all heads into a single attention map in the form of (num_tokens, num_tokens, num_layers) and merge them.
- Maintain the attention of each layer as they have their own unique meanings.
- Use the last token as a query (Q) to determine how much attention it receives from all previous tokens, and create a matrix of size (num_tokens, num_layers).
- Sum the attention values of all tokens in each line to calculate the total attention value for that line, and create a matrix of size (num_lines, num_layers). This matrix is called LayerwiseAttnMat.
Calculate the difference between the LayerwiseAttnMat of the highlighted prompt and the base prompt to create DiffAttnMat. Instead of looking at the differences across all lines, we extract only the data from the ‘instruction’ and ‘highlighted line’ where the actual changes are expected to be the largest, and create the final
VulnAttnMat.
3.3 Vulnerability Line Localization
The final step is to select the lines with actual vulnerabilities based on the patterns in VulnAttnMat. While it is possible to rank them simply by the sum of attention changes, it is difficult to apply consistent criteria across languages because the vulnerability patterns in C and Python are different. Furthermore, this is just a “suspicious ranking,” not an accurate judgment such as “this line has an 80% probability of being vulnerable!” Therefore, LOVA uses a deep learning model called Bi-LSTM at this stage. (Ugh… it’s getting more and more complicated…)
- First, we create a long vector from the
VulnAttnMatcalculated for each line. - We feed this vector sequence into the Bi-LSTM model as input. The reason we use Bi-LSTM is that when determining whether a specific line (A) is suspicious, it is more accurate to compare it with the attention patterns of the preceding and following lines (B, C). In other words, it considers the context of the entire code in both directions.
- The model ultimately outputs a “suspicious score” between 0 and 1 for each line, and if this score exceeds 0.5, it is judged to be vulnerable code.
4. Results
The tests were conducted using the Big-Vul, SmartFix, and CVEFixes benchmarks, utilizing models with 10B or less, such as Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.2, and Phi3.5-mini-instruct.
- LOVA demonstrated superior vulnerability location identification capabilities compared to existing LLM direct output methods, achieving up to a 5x performance improvement based on F1-score, especially in long code contexts.
- LOVA achieved excellent vulnerability location identification results across various programming languages, showing up to a 14.6x improvement.
- LOVA is applicable to various LLM architectures and shows consistent results.
Overall, it shows impressive performance. It was also good to compare it with various techniques such as CoT, MoA, and rStar, assuming that the same model was used. Above all, I think the attempt to use the self-attention mechanism for vulnerability detection for the first time is meaningful.
5. Areas for improvement
- Lack of comparison with larger models
- This paper tested using Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.2, and Phi3.5-mini-instruct, but there is no comparison with larger models.
- To use the method described in this paper, an attention matrix must be created for each code line, which increases the time required and the number of matrices to be computed. I suspect that the hardware was insufficient to handle larger models.
- In that case, it might be worth comparing it with the vanilla output of a larger model. (Oh, maybe I should try that myself…) Even if it only comes out as “comparable to the vanilla output of a larger model,” it would still be meaningful, right?
- This paper tested using Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.2, and Phi3.5-mini-instruct, but there is no comparison with larger models.
- Lack of comparison of power efficiency or computational cost
- LOVA highlights each code line individually to generate multiple versions of prompts, calculates the differences in attention maps between them, and goes through several other steps. Additionally, dimension reduction and the use of a Bi-LSTM classifier can increase complexity.
- This paper lacks mention of the time and financial costs incurred when applied to actual large-scale software projects. While dataset comparisons are useful for performance comparisons, it would be helpful to include measurements of how much additional computation is required as the amount of code increases. (The paper mentions that contexts exceeding 4,000 tokens were filtered to comply with LLM input constraints.)
- LOVA highlights each code line individually to generate multiple versions of prompts, calculates the differences in attention maps between them, and goes through several other steps. Additionally, dimension reduction and the use of a Bi-LSTM classifier can increase complexity.
Well… I’ll wrap up this post here. I considered developing it further into a second part… but my current life won’t allow it. Haha. Then I’ll be back for the next part! (Now I really need to watch Usenix…)

본 글은 CC BY-SA 4.0 라이선스로 배포됩니다. 공유 또는 변경 시 반드시 출처를 남겨주시기 바랍니다.