[Research] LLM Security & Safety Part 2. VulBinLLM Review(KR)

안녕하세요! 무려 6개월만에 찾아온…. j0ker 입니다! 2025년 상반기에 글이 없었던 이유는… 너무 바빴습니다… ㅎㅎ 바쁜 와중에도 LLM 관련 트랜드는 팔로업을 조금씩 하고 있었는데, 점점 더 많은 논문과 기술들이 나오니까 따라가기가 벅찹니다… 사람 살려… 일은 언제해…
그래서 전체적인 트랜드를 정리하기보다는 당분간은 간단하게 읽었던 것들을 정리해볼까 합니다. 오늘 다룰 논문은 “VulBinLLM: LLM-powered Vulnerability Detection for Stripped Binaries” 입니다. LLM으로 Stripped Binary 취약점을 찾는다는 소리인데… 이게 진짜 된다고? 라는 생각으로 읽어보기 시작했습니다.

잘하자…?
1. LLM을 활용해 취약점을 찾을 수 있을까?
며칠 전 Hackyboiz 오픈세미나에서 fandu님이 발표했던 주제죠? “야, 이거 사람이 읽기 힘드니까 LLM 시켜보면 안 돼?” 라는 아주 단순하지만 강력한 아이디어죠. 작년 AIxCC에서 Team Atlanta가 SQLite에서 제로데이를 찾은적도 있고, Project0에서도 취약점 찾았다고 하고… 이제 X에서도 LLM을 활용해 Linux SMB에서 제로데이 취약점을 찾았다는 글도 나왔습니다.
이 글이 X(구 트위터)에서 꽤 이슈가 되었습니다.
엄청난 좋아요와 리트윗수…. 우리 팀 계정도 많이 사랑해주세요…! @hackyboiz
이렇게 LLM을 활용해 제로데이를 찾을 수 있다는 너무 확실해 보입니다.
2. Stripped Binary
먼저 ‘Stripped Binary’가 뭔지 알아야겠죠? 우리가 보통 C나 C++ 코드를 짜서 컴파일하면 실행 파일(바이너리)이 뿅 하고 나오잖아요? 디버깅할 때는 함수 이름이나 변수 이름 같은 정보(심볼)가 다 들어있어서 분석하기가 편합니다.
근데 배포할 때는? 용량도 줄이고, 무엇보다 저희 같은 해커들이 분석하기 어렵게 만들려고 이 정보들을 싹 다 날려버립니다. 이게 바로 ‘Stripped Binary’에요. 함수 이름은 sub_401000 이딴 식으로 바뀌고, 변수가 뭔지도 모르겠고… 이걸 분석하는 건 진짜 끔찍한 일입니다. 시간과 노력이 엄청나게 갈려나가죠. 처음 CTF나 버그헌팅을 할 때 스트립된 바이너리만 보다가 오픈소스 취약점을 분석해야 할 기회가 있었는데, 정말 신세계였습니다 ㅋㅋ 아니 분석이 이렇게 쉽다고?(그래서 그 때부터 오픈소스에서 취약점을 찾고 있는…)
3. 암튼 그래서 LLM으로 취약점을 어떻게 찾겠다는건데?
이 논문의 핵심 목표는 LLM을 이용해서 Stripped Binary에서 취약점을 자동으로 찾아내는 시스템, VulBinLLM을 만드는 것입니다. 근데 그냥 디컴파일한 코드를 복붙해서 LLM에 “야, 취약점 찾아줘” 하면 잘 될까요? 네, 간단한 코드에서는 됩니다. 하지만 더 크고 방대한 양의 코드에서는? 그것도 stripped 바이너리라 함수명, 변수명도 제대로 되어 있지 않다면? 헛소리하기 딱 좋죠. 이 논문의 진짜 기여점은 바로 이 ‘어떻게?’를 해결하는 방법에 있습니다.
논문에서는 이 문제를 해결하기 위해 아래와 같은 체계적인 구조를 설계했습니다.
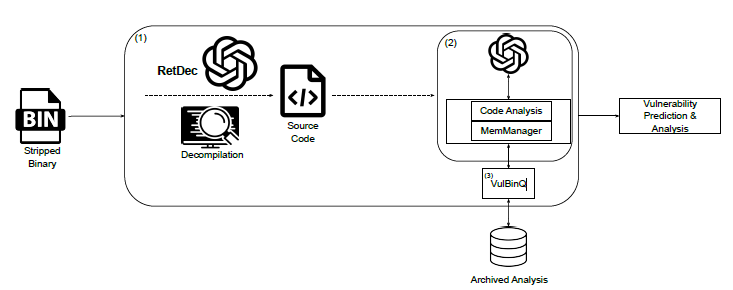
그냥 바이너리를 LLM에 넣는 게 아니라 디컴파일 -> 최적화 -> 장기 기억 생성 -> LLM 분석 이라는 명확한 파이프라인을 구축했습니다. 특히 ‘최적화’와 ‘장기 기억’ 부분이 이 연구의 핵심이라고 할 수 있습니다.
1) 디컴파일 최적화 (Decompilation Optimization): LLM을 위한 코드 정제
첫 번째 핵심은 ‘디컴파일 최적화’입니다. 아래 예시는 이 과정을 아주 명확하게 보여주는 예시입니다.
최적화 전(Ghidra):
void multiplyMatrix(long param_1, long param_2)
{
local_10 = *(long *)(in_FS_OFFSET + 0x28);
for (*(long *)local_34 = 0; *(long *)local_34 < R1; local_34++) {
for (local_30 = 0; local_30 < C2; local_30++) {
(auStack_28)[(long)local_34 * C2 + (long)local_30] = 0;
for (local_2c = 0; local_2c < R2; local_2c++) {
auStack_28[(long)local_34 * C2 + (long)local_30] += *(int *)((long)local_2c * 0xc + param_2 + (long)local_30 * 4)* *(int *)((long)local_34 * 8 + param_1 + (long)local_2c * 4);
}
}
}
}보시다시피 변수 이름은 param_1, local_34, R2 처럼 의미가 없고, 여러 개의 루프문이 사용되긴 하지만 어떤 맥락인지 바로 파악하기 어렵습니다.
최적화 후(VulBinLLM):
void multiplyMatrix(long input_matrix_1, long input_matrix_2)
{
// Initialize a matrix to store the result of matrix multiplication
int result_matrix[row_1][column_2] = {0};
// Iterate over each row and column of the result matrix
for (int current_row = 0; current_row < row_1; current_row++) {
for (int current_col = 0; current_col < column_2; current_col++) {
// Perform matrix multiplication by iterating over the shared dimension
for (int shared_dim = 0; shared_dim < row_2; shared_dim++) {
// Vulnerability: Potential pointer arithmetic issue if column_1 and row_2 are not properly allocated
// Multiply corresponding elements from the input matrices and accumulate the result
result_matrix[current_row][current_col] += *((int *)(input_matrix_2 + shared_dim * 12 + current_col * 4)) * *((int *)(input_matrix_1 + current_row * 8 + shared_dim * 4));
}
}
}
}최적화 후 코드는 완전히 달라집니다. local_10는 result_matrix로 되고 주석이 추가되면서 함수의 전체적인 맥락을 쉽게 파악할 수 있습니다. 그리고 잠재적인 취약점 정보도 제공해줍니다.
아쉽게도 논문에서는 이 과정에서 어떻게 프롬프트를 작성했는지 제공했는지는 안 나와있는데요. 그렇다면 이 결과를 다시 역으로 LLM에게 주고 프롬프트를 만들어 달라고 한다면 아래와 같이 나옵니다.
You are a world-class cybersecurity expert specializing in reverse engineering. Your primary task is to analyze raw C code decompiled by Ghidra from a stripped binary. You need to refactor this code to maximize readability and, most importantly, identify and annotate potential security vulnerabilities for a security audit.
The input code will lack original symbols, have generic variable names (e.g.,
param_1,local_10), and use complex pointer arithmetic. Your job is to semantically reconstruct the original developer’s intent and analyze it from a security perspective.Follow these steps precisely:
- Semantic Analysis & Renaming:
- Infer the high-level purpose of the function (e.g., string copy, matrix multiplication, network packet processing).
- Rename the function and its parameters (
param_1,param_2, etc.) to reflect their inferred purpose (e.g.,multiplyMatrix,input_matrix_1,input_matrix_2).- Rename local variables (
local_...,auStack_...) to descriptive names based on their usage (e.g.,result_matrix,current_row,current_col).
>Code Refactoring for Readability:
- Convert complex pointer arithmetic into more intuitive array or struct notation. For example, transform
*(int *)((long)local_2c * 0xc + param_2 + (long)local_30 * 4)into a clearer form likeinput_matrix_2[shared_dim][current_col].- Reconstruct data structures. If memory access patterns suggest a multi-dimensional array, represent it as such.
- Simplify control flow and logic where possible without changing the functionality.
Vulnerability Identification & Annotation:
- Scrutinize the code for common C/C++ vulnerabilities, including but not limited to:
- Buffer Overflows/Underflows: Unchecked indexing or pointer arithmetic.
- Integer Overflows/Underflows: Operations that could lead to wrapping.
- Null Pointer Dereferences: Use of pointers that could be null.
- Use-After-Free: Accessing memory after it has been freed.
- Information Leakage: Exposing sensitive data.
- For each potential vulnerability found, insert a comment in the line immediately preceding the vulnerable code. The comment must start with
// Vulnerability:and provide a concise explanation of the potential risk.Add Explanatory Comments:
- Add a high-level comment at the beginning of the function explaining its overall purpose.
- Add comments to explain complex or non-obvious parts of the algorithm.
Here is an example of the desired transformation:
[INPUT] Raw Decompiled Code from Ghidra:
>void multiplyMatrix(long param_1, long param_2) >{ local_10 = *(long *)(in_FS_OFFSET + 0x28); for (*(long *)local_34 = 0; *(long *)local_34 < R1; local_34++) { for (local_30 = 0; local_30 < C2; local_30++) { (auStack_28)[(long)local_34 * C2 + (long)local_30] = 0; for (local_2c = 0; local_2c < R2; local_2c++) { auStack_28[(long)local_34 * C2 + (long)local_30] += *(int *)((long)local_2c * 0xc + param_2 + (long)local_30 * 4)* *(int *)((long)local_34 * 8 + param_1 + (long)local_2c * 4); } } } >}[OUTPUT] Optimized Code for Vulnerability Analysis:
>void multiplyMatrix(long input_matrix_1, long input_matrix_2) >{ // Initialize a matrix to store the result of matrix multiplication int result_matrix[row_1][column_2] = {0}; // Iterate over each row and column of the result matrix for (int current_row = 0; current_row < row_1; current_row++) { for (int current_col = 0; current_col < column_2; current_col++) { // Perform matrix multiplication by iterating over the shared dimension for (int shared_dim = 0; shared_dim < row_2; shared_dim++) { // Vulnerability: Potential out-of-bounds access if matrix dimensions (R1, C2, R2) are not validated // before this function call. The pointer arithmetic relies on these external constants. // Multiply corresponding elements from the input matrices and accumulate the result. result_matrix[current_row][current_col] += *((int *)(input_matrix_2 + shared_dim * 12 + current_col * 4)) * *((int *)(input_matrix_1 + current_row * 8 + shared_dim * 4)); } } } >}
Now, apply this process to the following Ghidra decompiled code. Provide ONLY the optimized C code as your output.
[YOUR CODE TO ANALYZE GOES HERE]
이렇게 예시까지 포함되서 프롬프트가 생성됩니다. 프롬프트가 잘 동작하는지 테스트를 해봐야하니 예시를 제외하고 Gemini에 넣어보죠.
결과:
/**
* @brief Performs matrix multiplication of matrix_A (R1 x R2) and matrix_B (R2 x C2).
*
* This function reconstructs the logic for matrix multiplication. It takes pointers to two
* matrices, `matrix_A_ptr` and `matrix_B_ptr`, and computes their product. The resulting
* (R1 x C2) matrix is stored in a local stack variable `result_matrix`.
*
* The dimensions R1 (rows of A), R2 (cols of A / rows of B), and C2 (cols of B)
* are assumed to be externally defined constants (e.g., preprocessor macros),
* which is a common source of vulnerabilities.
*
* Based on the memory access patterns from the decompilation:
* - matrix_A is treated as an [R1][R2] integer matrix.
* - matrix_B is treated as an [R2][C2] integer matrix.
*
* Note: The original stack canary check (`in_FS_OFFSET`) has been removed for clarity
* as it is a compiler-generated security mechanism and not part of the original logic.
*
* @param matrix_A_ptr Pointer to the first input matrix (assumed to be flattened R1xR2).
* @param matrix_B_ptr Pointer to the second input matrix (assumed to be flattened R2xC2).
*/
void multiply_matrices(int *matrix_A_ptr, int *matrix_B_ptr) {
// Vulnerability: Null Pointer Dereference
// The function does not check if input pointers are NULL before use. If either
// `matrix_A_ptr` or `matrix_B_ptr` is NULL, dereferencing them inside the loops
// will cause a segmentation fault and crash the application.
// To improve readability, we cast the flat input pointers to 2D array pointers.
// This mirrors the structured access intended by the original developer.
// The pointer arithmetic `(row * stride) + col_offset` is now `[row][col]`.
// The strides inferred from Ghidra (`* 8` for A, `* 0xc` for B) suggest R2=2 and C2=3.
int (*matrix_A)[R2] = (int (*)[R2])matrix_A_ptr;
int (*matrix_B)[C2] = (int (*)[C2])matrix_B_ptr;
// Vulnerability: Stack Buffer Overflow
// The result matrix is allocated on the stack with a size fixed at compile time
// via the macros R1 and C2. If the actual dimensions of the input matrices
// (determined by the caller) are larger than these compiled constants, the loops
// will write past the bounds of `result_matrix`, corrupting the stack.
int result_matrix[R1][C2];
// Iterate over each row of the first matrix (matrix_A).
for (int current_row = 0; current_row < R1; current_row++) {
// Iterate over each column of the second matrix (matrix_B).
for (int current_col = 0; current_col < C2; current_col++) {
// Initialize the target cell in the result matrix.
result_matrix[current_row][current_col] = 0;
// Calculate the dot product for the cell (current_row, current_col).
// This loop iterates over the shared dimension (columns of A and rows of B).
for (int shared_dim = 0; shared_dim < R2; shared_dim++) {
// Vulnerability: Integer Overflow
// The multiplication of two matrix elements can exceed the maximum value for an `int`,
// causing the value to wrap around (undefined behavior for signed integers).
// The subsequent accumulation into `result_matrix` could also overflow.
// Vulnerability: Out-of-Bounds Read
// The loops iterate based on the external constants R1, R2, and C2. If these
// constants do not match the actual allocated sizes of the buffers pointed to
// by `matrix_A_ptr` and `matrix_B_ptr`, this operation will read from
// out-of-bounds memory, leading to information leakage or a crash.
result_matrix[current_row][current_col] +=
matrix_A[current_row][shared_dim] * matrix_B[shared_dim][current_col];
}
}
}
// The function scope ends here. The `result_matrix` is destroyed upon returning.
// In a real-world scenario, its contents would likely have been copied to an
// output parameter pointer before the function returns.
}뭔가 생각보다 더 디테일하게 주는데요 뭐 어쨌든(?) 결과물은 괜찮아 보입니다 ㅋㅋ 너무 설명이 디테일하다거나 영어를 쓰는 등 디테일한 부분들은 더 수정하면 되겠죠.
2) 장기 기억 (Long-term Memory)
LLM의 고질적인 문제 중 하나가 입력 길이 제한(Context Window)입니다. 프로그램 전체 코드를 한 번에 넣어줄 수가 없으니, 코드를 잘게 쪼개서 물어봐야 하죠. 근데 이렇게 하면 전체적인 맥락을 놓치기 쉽습니다. A라는 함수가 B라는 함수를 호출하고, 그 결과가 C라는 변수에 영향을 미치는 복잡한 흐름을 파악하기 어렵다는 거죠.
VulBinLLM은 이 문제를 해결하기 위해 ‘장기 기억’이라는 개념을 도입했습니다. 코드의 중요한 부분(예: 함수 요약, 데이터 구조 등)을 미리 요약해서 저장해두고, LLM이 다른 코드 조각을 분석할 때 이 ‘기억’을 함께 참고하게 만드는 겁니다. 논문에 따르면 이 정보에는 프로그램의 목적에 대한 요약, 핵심 데이터 구조, 함수 호출 그래프(Call Graph) 등이 포함됩니다.
예를 들어 위 코드를 분석할 때, LLM은 다음과 같은 추가 정보를 함께 받게 됩니다.
- 프로그램 요약: “이 프로그램은 환경 변수로부터 사용자 입력을 받아 처리하는 테스트 프로그램이다.”
- 데이터 흐름: “
getenv함수를 통해 외부 입력이user_input변수에 저장되고, 이 변수는memcpy함수의 소스(source)로 사용된다.”
이러한 맥락 정보가 있으면, LLM은 user_input이 그냥 문자열이 아니라 ‘신뢰할 수 없는 외부 입력’이라는 점을 명확히 인지하고, 취약점을 더 정확하게 판단할 수 있게 됩니다.
마무리
오늘은 “VulBinLLM: LLM-powered Vulnerability Detection for Stripped Binaries” 논문 내용을 공부하면서 간단하게 정리해봤습니다. 사실 논문의 아쉬운 점이 좀 많습니다.
- 최신 LLM 모델을 활용하지 않았다: 이 부분은 여러 논문에서도 같이 보이는 단점입니다. 아무래도 모델의 개발 속도가 워낙 빠르다보니 설계하고 개발하고 테스트를 한 뒤에 논문을 쓰기 때문이지 않을까 싶습니다.
- 정말 신박한 아이디어일까…?: Stripped Binary 디컴파일 코드를 복구하는 논문은 이미 나와있습니다. 이 부분이 이 논문의 핵시 연구 가치일지에 대한 부분은 좀 의아합니다.
최근 LLM 관련 논문들이 너무 많이 나오기 때문에 정말 좋은 논문을 골라 읽기는 쉽지 않아 아이디어만 훑는 경우가 많긴합니다. 그래도 아이디어가 좋은 논문이 보이면 또 공부해서 올려보도록 하겠습니다 ㅎㅎ
그럼 또 언젠간… 다음 글로 돌아올게요!

본 글은 CC BY-SA 4.0 라이선스로 배포됩니다. 공유 또는 변경 시 반드시 출처를 남겨주시기 바랍니다.