[Research] LLM Security & Safety Part 2. VulBinLLM Review(EN)

Hello! It’s been 6 months since I’ve been back to …. I’m j0ker! The reason for the lack of posts in the first half of 2025 is… I was too busy… lol Even while I was busy, I was slowly following up on LLM-related trends, but as more and more papers and technologies come out, it’s hard to keep up… For God’s sake… When do you get to work?
So, rather than summarise the overall trend, I’ll just summarise what I’ve been reading for the time being. Today’s paper is “VulBinLLM: LLM-powered Vulnerability Detection for Stripped Binaries”. I started reading the paper with the thought that it’s about finding stripped binary vulnerabilities with LLM… is this really possible?

Try your best, LLM…
1. Can LLM be used to find vulnerabilities?
This is the topic that fandu presented at the Hackyboiz Open Seminar a few days ago. It’s a very simple but powerful idea: “Hey, can we LLM this because it’s hard for humans to read?” Team Atlanta found a zero-day vulnerability in SQLite at AIxCC last year, Project0 found a vulnerability… and now X also found a zero-day vulnerability in Linux SMB using LLM.
This article caused quite a stir on X (formerly Twitter).
Tons of likes and retweets…. Give our team account a lot of love too…! @hackyboiz
It seems too obvious that we can use LLMs to find zero-days.
2. Stripped Binary
First of all, you should know what a ‘Stripped Binary’ is, right? When we usually write C or C++ code and compile it, we get an executable (binary) file, right? When debugging, it’s easy to analyse because it contains all the information (symbols) like function names and variable names.
But when it’s deployed, it’s stripped of all this information to reduce the size and make it harder for hackers like us to analyse. This is what Stripped Binary is: function names are changed to sub_401000 or something like that, you don’t even know what the variables are… and analysing them is a real nightmare. When I was first doing CTF or bug hunting, I had a chance to analyse an open source vulnerability by looking at a stripped binary, and it was a new world… No, it’s so easy to analyse? (That’s why I’ve been looking for vulnerabilities in open source since then…)
3. So how are you going to find vulnerabilities with LLM?
The main goal of this thesis is to create VulBinLLM, a system that uses LLM to automatically find vulnerabilities in stripped binaries. But can we just paste the decompiled code and tell LLM “hey, find vulnerabilities” and it will work? Yes, for simple code. But on larger, more massive chunks of code? If it’s stripped binary and doesn’t even have proper function and variable names? It’s a recipe for bullshit. The real contribution of this paper is how to solve that “how?”.
In the thesis, we designed the following systematic structure to solve this problem.
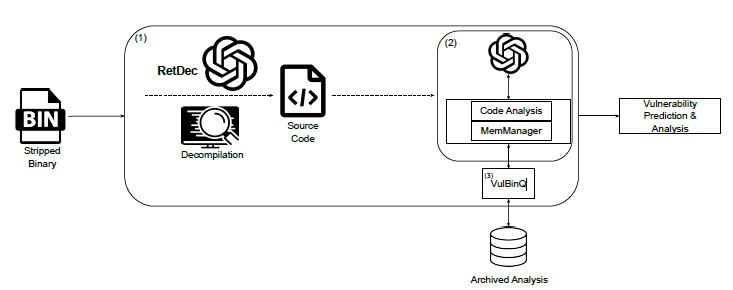
Instead of just putting binaries into LLM, we built a clear pipeline: Decompilation -> Optimisation -> Long-term memory generation -> LLM analysis. In particular, the ‘optimisation’ and ‘long-term memory’ parts are the core of this research.
1) Decompilation Optimisation: Refining code for LLM
The first key is ‘decompilation optimisation’. The example below illustrates this process very clearly.
Before Optimisation (Ghidra):
void multiplyMatrix(long param_1, long param_2)
{
local_10 = *(long *)(in_FS_OFFSET + 0x28);
for (*(long *)local_34 = 0; *(long *)local_34 < R1; local_34++) {
for (local_30 = 0; local_30 < C2; local_30++) {
(auStack_28)[(long)local_34 * C2 + (long)local_30] = 0;
for (local_2c = 0; local_2c < R2; local_2c++) {
auStack_28[(long)local_34 * C2 + (long)local_30] += *(int *)((long)local_2c * 0xc + param_2 + (long)local_30 * 4)* *(int *)((long)local_34 * 8 + param_1 + (long)local_2c * 4);
}
}
}
}As you can see, the variable names don’t make sense, like param_1, local_34, and R2, and although there are several loop statements used, it’s not immediately obvious what’s going on.
After optimisation (VulBinLLM):
void multiplyMatrix(long input_matrix_1, long input_matrix_2)
{
// Initialize a matrix to store the result of matrix multiplication
int result_matrix[row_1][column_2] = {0};
// Iterate over each row and column of the result matrix
for (int current_row = 0; current_row < row_1; current_row++) {
for (int current_col = 0; current_col < column_2; current_col++) {
// Perform matrix multiplication by iterating over the shared dimension
for (int shared_dim = 0; shared_dim < row_2; shared_dim++) {
// Vulnerability: Potential pointer arithmetic issue if column_1 and row_2 are not properly allocated
// Multiply corresponding elements from the input matrices and accumulate the result
result_matrix[current_row][current_col] += *((int *)(input_matrix_2 + shared_dim * 12 + current_col * 4)) * *((int *)(input_matrix_1 + current_row * 8 + shared_dim * 4));
}
}
}
}After the optimisation, the code looks completely different: local_10 becomes result_matrix and comments are added, making it easier to see the full context of the function. They also provide information about potential vulnerabilities.
Unfortunately, the paper doesn’t provide how the prompts were created in this process, but if we reverse this back to LLM and ask him to create the prompts, it looks like this
You are a world-class cybersecurity expert specializing in reverse engineering. Your primary task is to analyze raw C code decompiled by Ghidra from a stripped binary. You need to refactor this code to maximize readability and, most importantly, identify and annotate potential security vulnerabilities for a security audit.
The input code will lack original symbols, have generic variable names (e.g.,
param_1,local_10), and use complex pointer arithmetic. Your job is to semantically reconstruct the original developer’s intent and analyze it from a security perspective.Follow these steps precisely:
Semantic Analysis & Renaming:
- Infer the high-level purpose of the function (e.g., string copy, matrix multiplication, network packet processing).
- Rename the function and its parameters (
param_1,param_2, etc.) to reflect their inferred purpose (e.g.,multiplyMatrix,input_matrix_1,input_matrix_2).- Rename local variables (
local_...,auStack_...) to descriptive names based on their usage (e.g.,result_matrix,current_row,current_col).Code Refactoring for Readability:
- Convert complex pointer arithmetic into more intuitive array or struct notation. For example, transform
*(int *)((long)local_2c * 0xc + param_2 + (long)local_30 * 4)into a clearer form likeinput_matrix_2[shared_dim][current_col].- Reconstruct data structures. If memory access patterns suggest a multi-dimensional array, represent it as such.
- Simplify control flow and logic where possible without changing the functionality.
Vulnerability Identification & Annotation:
- Scrutinize the code for common C/C++ vulnerabilities, including but not limited to:
- Buffer Overflows/Underflows: Unchecked indexing or pointer arithmetic.
- Integer Overflows/Underflows: Operations that could lead to wrapping.
- Null Pointer Dereferences: Use of pointers that could be null.
- Use-After-Free: Accessing memory after it has been freed.
- Information Leakage: Exposing sensitive data.
- For each potential vulnerability found, insert a comment in the line immediately preceding the vulnerable code. The comment must start with
// Vulnerability:and provide a concise explanation of the potential risk.Add Explanatory Comments:
- Add a high-level comment at the beginning of the function explaining its overall purpose.
- Add comments to explain complex or non-obvious parts of the algorithm.
Here is an example of the desired transformation:
[INPUT] Raw Decompiled Code from Ghidra:
>void multiplyMatrix(long param_1, long param_2) >{ local_10 = *(long *)(in_FS_OFFSET + 0x28); for (*(long *)local_34 = 0; *(long *)local_34 < R1; local_34++) { for (local_30 = 0; local_30 < C2; local_30++) { (auStack_28)[(long)local_34 * C2 + (long)local_30] = 0; for (local_2c = 0; local_2c < R2; local_2c++) { auStack_28[(long)local_34 * C2 + (long)local_30] += *(int *)((long)local_2c * 0xc + param_2 + (long)local_30 * 4)* *(int *)((long)local_34 * 8 + param_1 + (long)local_2c * 4); } } } >}[OUTPUT] Optimized Code for Vulnerability Analysis:
>void multiplyMatrix(long input_matrix_1, long input_matrix_2) >{ // Initialize a matrix to store the result of matrix multiplication int result_matrix[row_1][column_2] = {0}; // Iterate over each row and column of the result matrix for (int current_row = 0; current_row < row_1; current_row++) { for (int current_col = 0; current_col < column_2; current_col++) { // Perform matrix multiplication by iterating over the shared dimension for (int shared_dim = 0; shared_dim < row_2; shared_dim++) { // Vulnerability: Potential out-of-bounds access if matrix dimensions (R1, C2, R2) are not validated // before this function call. The pointer arithmetic relies on these external constants. // Multiply corresponding elements from the input matrices and accumulate the result. result_matrix[current_row][current_col] += *((int *)(input_matrix_2 + shared_dim * 12 + current_col * 4)) * *((int *)(input_matrix_1 + current_row * 8 + shared_dim * 4)); } } } >}
Now, apply this process to the following Ghidra decompiled code. Provide ONLY the optimized C code as your output.
[YOUR CODE TO ANALYZE GOES HERE]
This creates a prompt, complete with an example. We need to test the prompt to make sure it works, so let’s remove the example and put it into Gemini.
Result:
/**
* @brief Performs matrix multiplication of matrix_A (R1 x R2) and matrix_B (R2 x C2).
*
* This function reconstructs the logic for matrix multiplication. It takes pointers to two
* matrices, `matrix_A_ptr` and `matrix_B_ptr`, and computes their product. The resulting
* (R1 x C2) matrix is stored in a local stack variable `result_matrix`.
*
* The dimensions R1 (rows of A), R2 (cols of A / rows of B), and C2 (cols of B)
* are assumed to be externally defined constants (e.g., preprocessor macros),
* which is a common source of vulnerabilities.
*
* Based on the memory access patterns from the decompilation:
* - matrix_A is treated as an [R1][R2] integer matrix.
* - matrix_B is treated as an [R2][C2] integer matrix.
*
* Note: The original stack canary check (`in_FS_OFFSET`) has been removed for clarity
* as it is a compiler-generated security mechanism and not part of the original logic.
*
* @param matrix_A_ptr Pointer to the first input matrix (assumed to be flattened R1xR2).
* @param matrix_B_ptr Pointer to the second input matrix (assumed to be flattened R2xC2).
*/
void multiply_matrices(int *matrix_A_ptr, int *matrix_B_ptr) {
// Vulnerability: Null Pointer Dereference
// The function does not check if input pointers are NULL before use. If either
// `matrix_A_ptr` or `matrix_B_ptr` is NULL, dereferencing them inside the loops
// will cause a segmentation fault and crash the application.
// To improve readability, we cast the flat input pointers to 2D array pointers.
// This mirrors the structured access intended by the original developer.
// The pointer arithmetic `(row * stride) + col_offset` is now `[row][col]`.
// The strides inferred from Ghidra (`* 8` for A, `* 0xc` for B) suggest R2=2 and C2=3.
int (*matrix_A)[R2] = (int (*)[R2])matrix_A_ptr;
int (*matrix_B)[C2] = (int (*)[C2])matrix_B_ptr;
// Vulnerability: Stack Buffer Overflow
// The result matrix is allocated on the stack with a size fixed at compile time
// via the macros R1 and C2. If the actual dimensions of the input matrices
// (determined by the caller) are larger than these compiled constants, the loops
// will write past the bounds of `result_matrix`, corrupting the stack.
int result_matrix[R1][C2];
// Iterate over each row of the first matrix (matrix_A).
for (int current_row = 0; current_row < R1; current_row++) {
// Iterate over each column of the second matrix (matrix_B).
for (int current_col = 0; current_col < C2; current_col++) {
// Initialize the target cell in the result matrix.
result_matrix[current_row][current_col] = 0;
// Calculate the dot product for the cell (current_row, current_col).
// This loop iterates over the shared dimension (columns of A and rows of B).
for (int shared_dim = 0; shared_dim < R2; shared_dim++) {
// Vulnerability: Integer Overflow
// The multiplication of two matrix elements can exceed the maximum value for an `int`,
// causing the value to wrap around (undefined behavior for signed integers).
// The subsequent accumulation into `result_matrix` could also overflow.
// Vulnerability: Out-of-Bounds Read
// The loops iterate based on the external constants R1, R2, and C2. If these
// constants do not match the actual allocated sizes of the buffers pointed to
// by `matrix_A_ptr` and `matrix_B_ptr`, this operation will read from
// out-of-bounds memory, leading to information leakage or a crash.
result_matrix[current_row][current_col] +=
matrix_A[current_row][shared_dim] * matrix_B[shared_dim][current_col];
}
}
}
// The function scope ends here. The `result_matrix` is destroyed upon returning.
// In a real-world scenario, its contents would likely have been copied to an
// output parameter pointer before the function returns.
}It gives more details than I thought, but anyway(?) the result looks good lol I think I can fix some details like too detailed description and using English.
2) Long-term Memory
One of the inherent problems with LLM is the Context Window. You can’t give us the whole programme in one go, so we have to ask you in chunks, but it’s easy to lose context. It’s hard to see the complex flow of how function A calls function B, and the result affects variable C.
VulBinLLM introduces the concept of “long-term memory” to solve this problem. The idea is to store a summary of important parts of the code (e.g. function summaries, data structures, etc.) in advance, and let LLM refer to this ‘memory’ when analysing other code fragments. According to the paper, this information includes a summary of the program’s purpose, key data structures, and function call graphs.
For example, when analysing the code above, the LLM would be presented with the following additional information
- Programme Summary:** “This is a test program that accepts user input from environment variables and processes it.”
- Data flow: “The external input is stored in the
user_input' variable via thegetenv’ function, which is used as a source for the `memcpy’ function.”
With this contextual information, LLM will clearly recognise that user_input is an ‘untrusted external input’ and not just a string, and will be able to more accurately determine the vulnerability.
Wrapping up
Today, I’ve been studying the paper “VulBinLLM: LLM-powered Vulnerability Detection for Stripped Binaries” and I’ve made a quick summary of the paper, but there are a few things that I think are missing.
- It doesn’t use the latest LLM model: This is a common shortcoming in many papers. I think it’s because the development speed of the model is so fast that they design, develop, test, and then write the paper.
- Is it really a novel idea…? There are already papers on recovering stripped binary decompiled code. I’m a bit dubious about the hacky research value of this thesis.
Since there are so many LLM-related papers recently, it is not easy to pick out a really good paper and read it, so I often skim the idea. Still, if I see a paper with a good idea, I will study it again and post it lol.
Until next time… I’ll be back!

본 글은 CC BY-SA 4.0 라이선스로 배포됩니다. 공유 또는 변경 시 반드시 출처를 남겨주시기 바랍니다.